记一次项目线上的内存暴增以及解决办法
前景提要
项目上线了,在开发时一切正常,运行正常,项目上线后,还没运行一个星期,发现项目运行越来越慢,进入后台管理界面用了30秒。当时刚听到这个消息,“怎么可能!!!内测,都还没几个人用呢”,直到我自己打开系统,等了好久才进入系统,信了。
线索追踪
查看错误日志
知道系统出现了问题,但是线上的系统我又碰不到,申请下,运维人员带我去了机房,真是戒备森严。查看错误日志,没有关键的信息。想让运维人员给我把错误日志拿出来,我回去研究研究,被语气很强硬的直接否决了。。。
查看程序运行状态
使用
px -aux |grep ***
定位程序pid
top -p <PID>
查看程序占用内存 虽然这个系统比较大,但是占用的内存达到了4GB,真是可怕。
jmap查看线上程序运行的内存信息
jmap -histo <PID>
刷刷刷一段文字,上一张本地演示的图,是之后在本地复现的截图
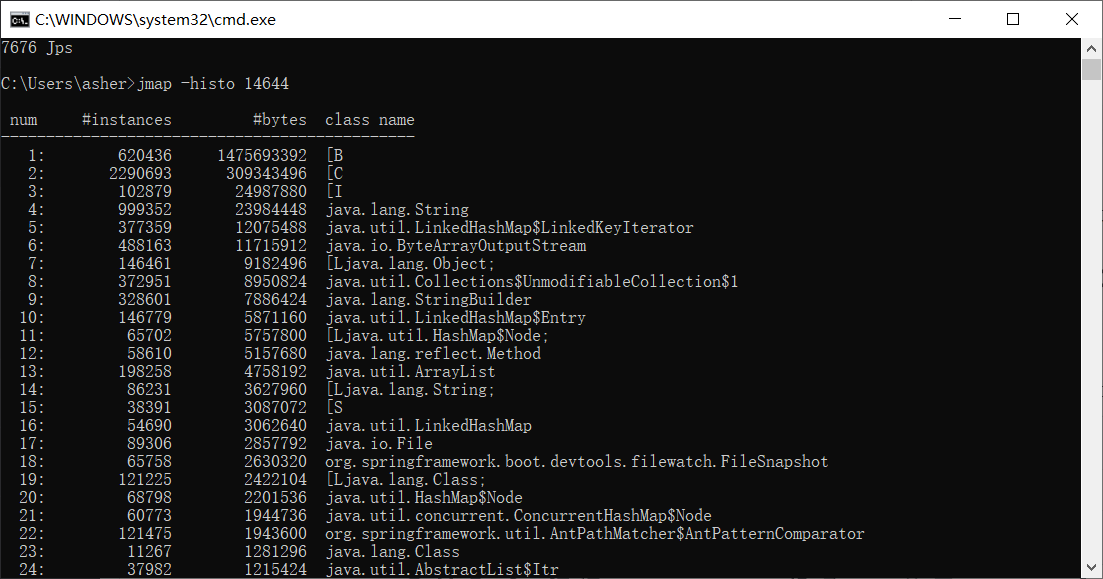 简单的说说这个图里有啥
简单的说说这个图里有啥
- num:序号
- instances:实例对象
- bytes:占用的大小
- class name:类名称,B就是byte[],C就是char[],I就是int[],如果还有S的话就是short[]了,
发现了情况, “byte[]怎么这么多!!!项目中有用到什么byte[]吗?,好像没有啊。可能是其他对象产生的,比如文件流,写入写出之类的。啊,我想到了,不会有人流的处理没有close掉吧“ 询问了运维人员能不能拍照,既然拿不出里面的文件,拍照可以的吧。 运维:- 不行!想什么呢!
没办法,再看看其他的
看看堆信息
jmap -heap <PID>
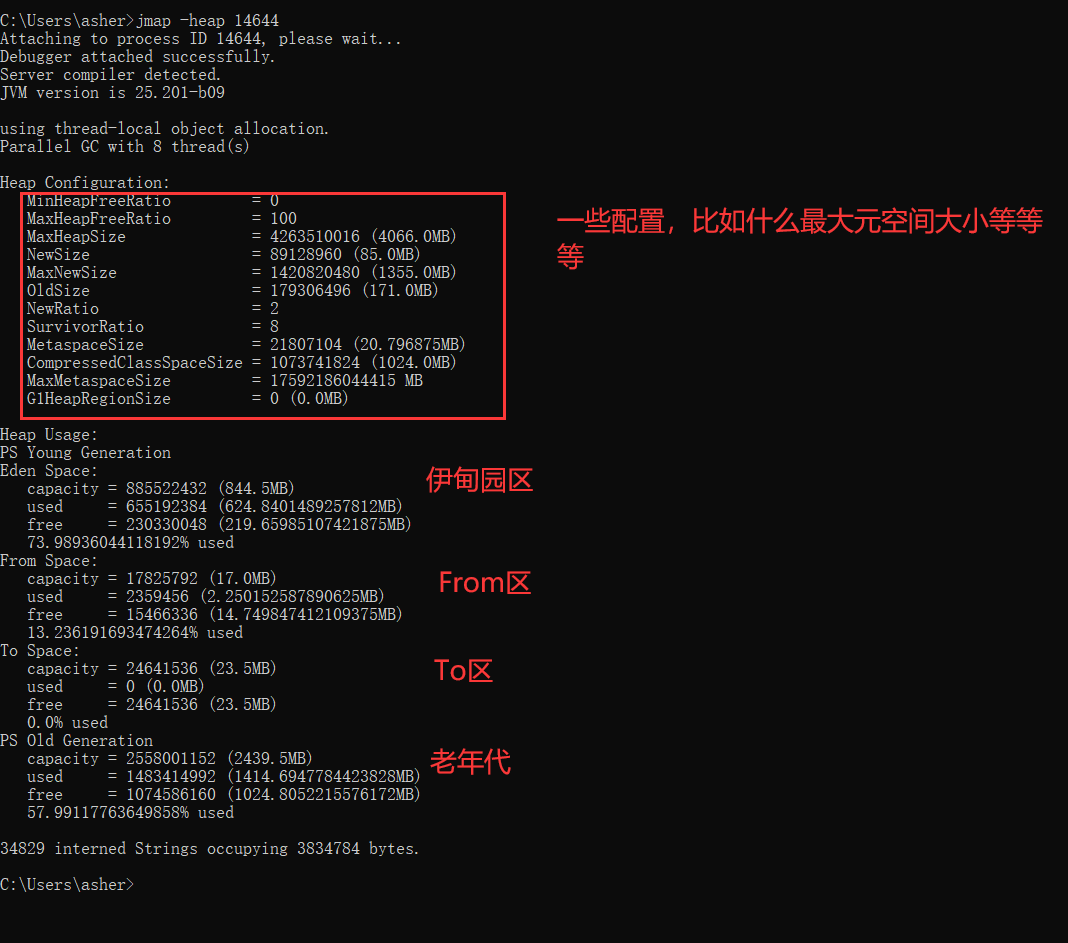 当时的情况记不太清了,随便看了几眼,脑袋还在想着之前byte[]的事。
当时的情况记不太清了,随便看了几眼,脑袋还在想着之前byte[]的事。
既然都来了,那多看点其他的信息,
查看gc的情况
jstat -gc <PID> 1000(间隔时间) 10000(次数)
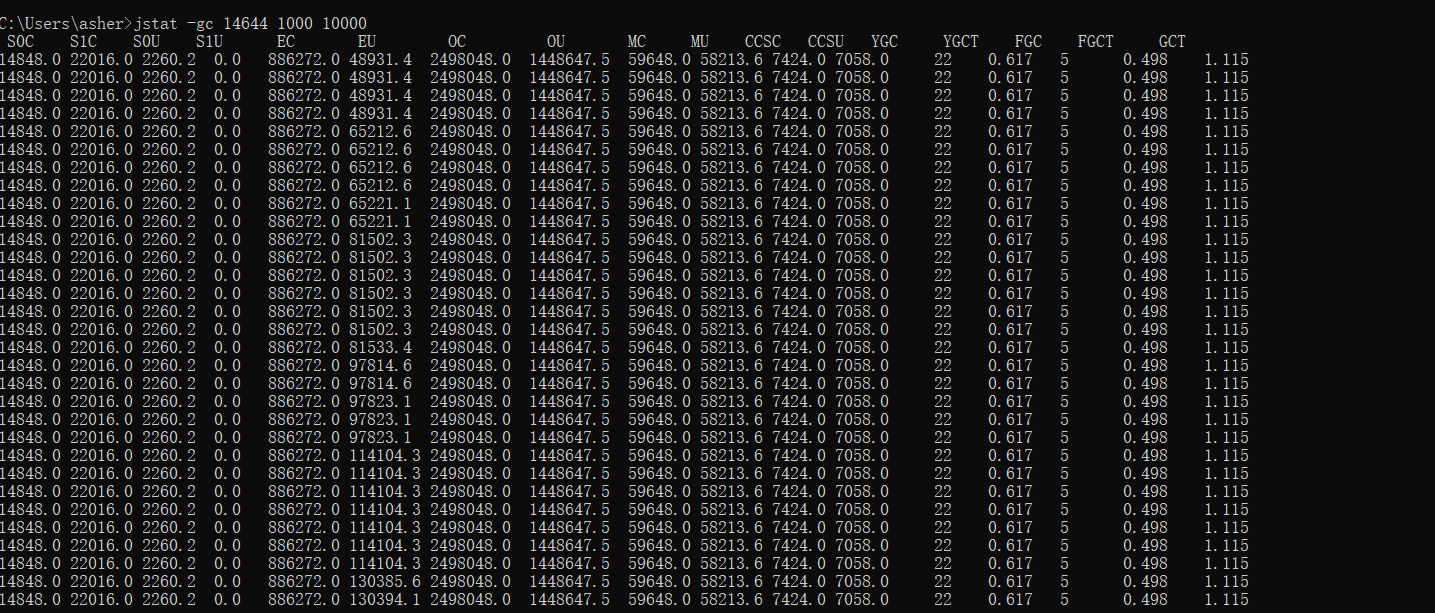 图片里面
图片里面
- S0C:第一个幸存区大小
- S1C:第二个幸存区大小
- S0U:第一个幸存区的使用大小
- S1U:第二个幸存区的使用大小
- EC:伊甸园的大小
- EU:伊甸园区的使用大小
- OC:老年代大小
- OU:老年代使用大小
- MC:方法区大小(元空间)
- MU:方法区使用大小
- CCSC:压缩类空间使用大小
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间,单位:s
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间,单位:s
- GCT:垃圾回收消耗总时间,单位:s
当时的情况是,Full GC触发的数量极其之多,然后我直接用手机请求一次外网地址看看,还没点几下功能,直接触发Full GC了。一脸黑线,还好运维没看懂我在干嘛,不然真的够尴尬的。 一般来说,Full GC几小时触发,或者几天触发一次才正常,而young GC几分钟,几小时触发一次才正常,这种情况下,记下了我刚刚点的那几个功能,那部分的代码很有可能有问题。
感觉看的差不多了,运维也一直催我ok没有,因为是下班时间,再看看有没有死锁吧。
使用jstack查找死锁
顺便写一下jstack的使用,那会儿还好我带着平板去的,可以直接查我平板上的资料
1.使用top -p <PID>,显示java进程的内存情况,pid是java进程号
2.按H,获�取每个线程的内存情况
3.找到内存和cpu占用最高的线程id
4.转为16进制得到线程的16进制表示0x2365
5.执行jstack <PID>|grep -A 10 2365,得到线程堆栈信息中2365这个线程所在行的后面10行
6.查看对应的堆栈信息找出可能存在问题的代码
ok,没有死锁
问题重现
其实这部分在本地进行重现的话还是很容易就做到了,毕竟线上内存32G的机器不到7天就出问题,本地可以直接使用工具jvisualvm,jprofile等实时监控。 这里我使用的就是jprofile了,还是一个挺强大的工具。
jprofile使用
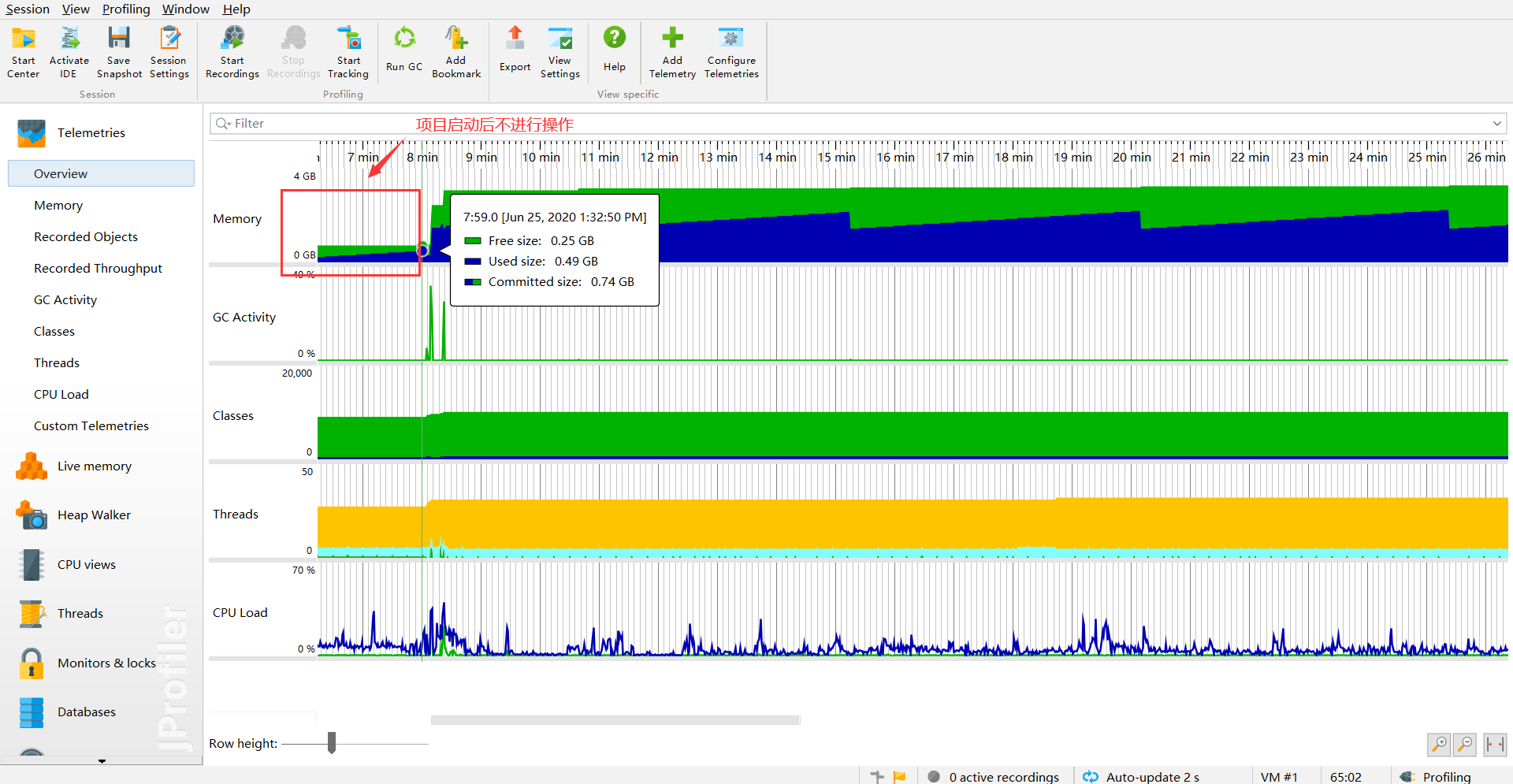
项目启动
当项目进行启动后,不进行访问,还是挺正常的,used size不超过500M
正常请求
开始进行请求访问,瞬间就增加到2G
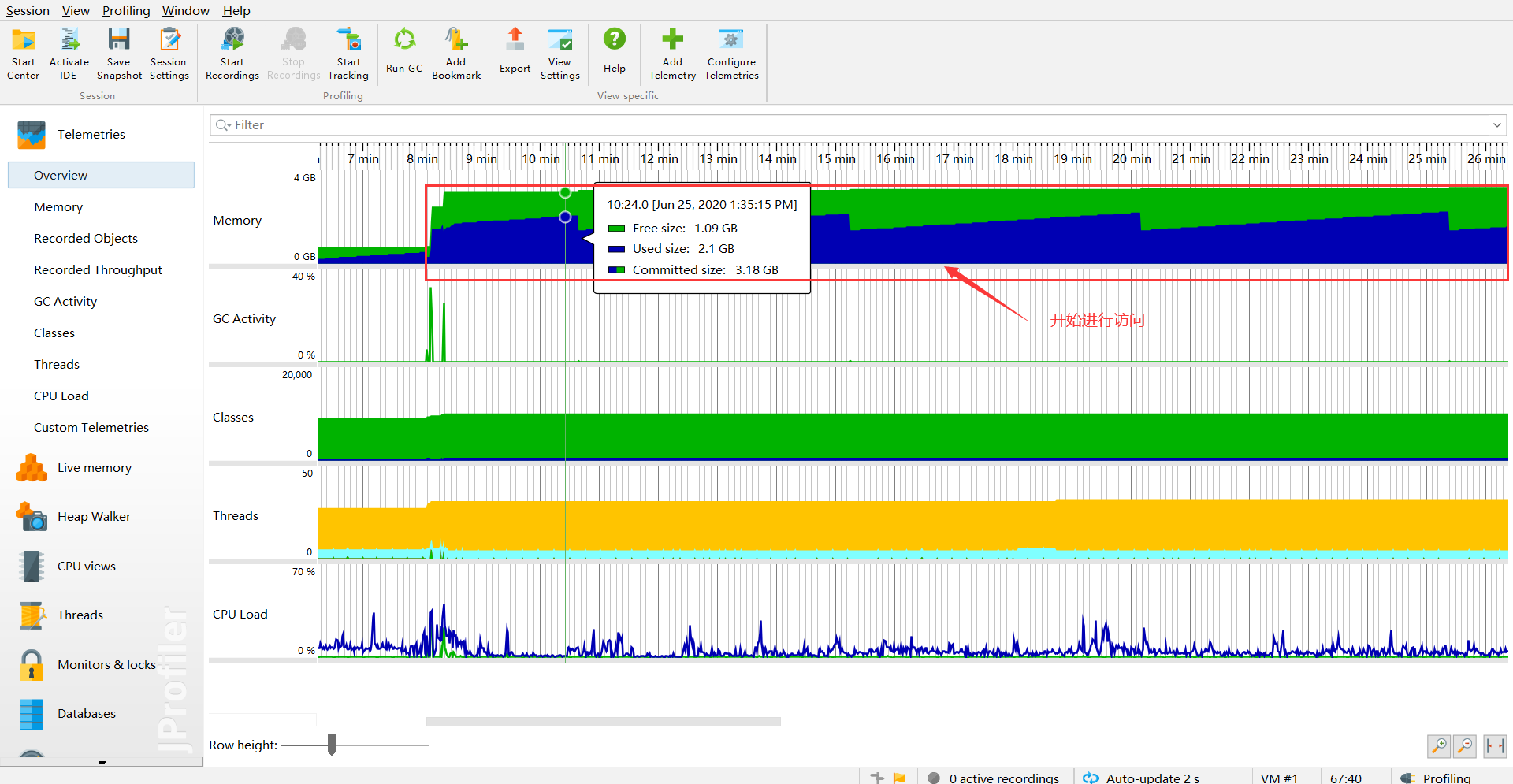
手动触发GC
手动触发一次GC后,那么剩下来的,那就肯定是不能被GC回收的垃圾对象了

查看live memory
果不其然,就是byte[]占的最多
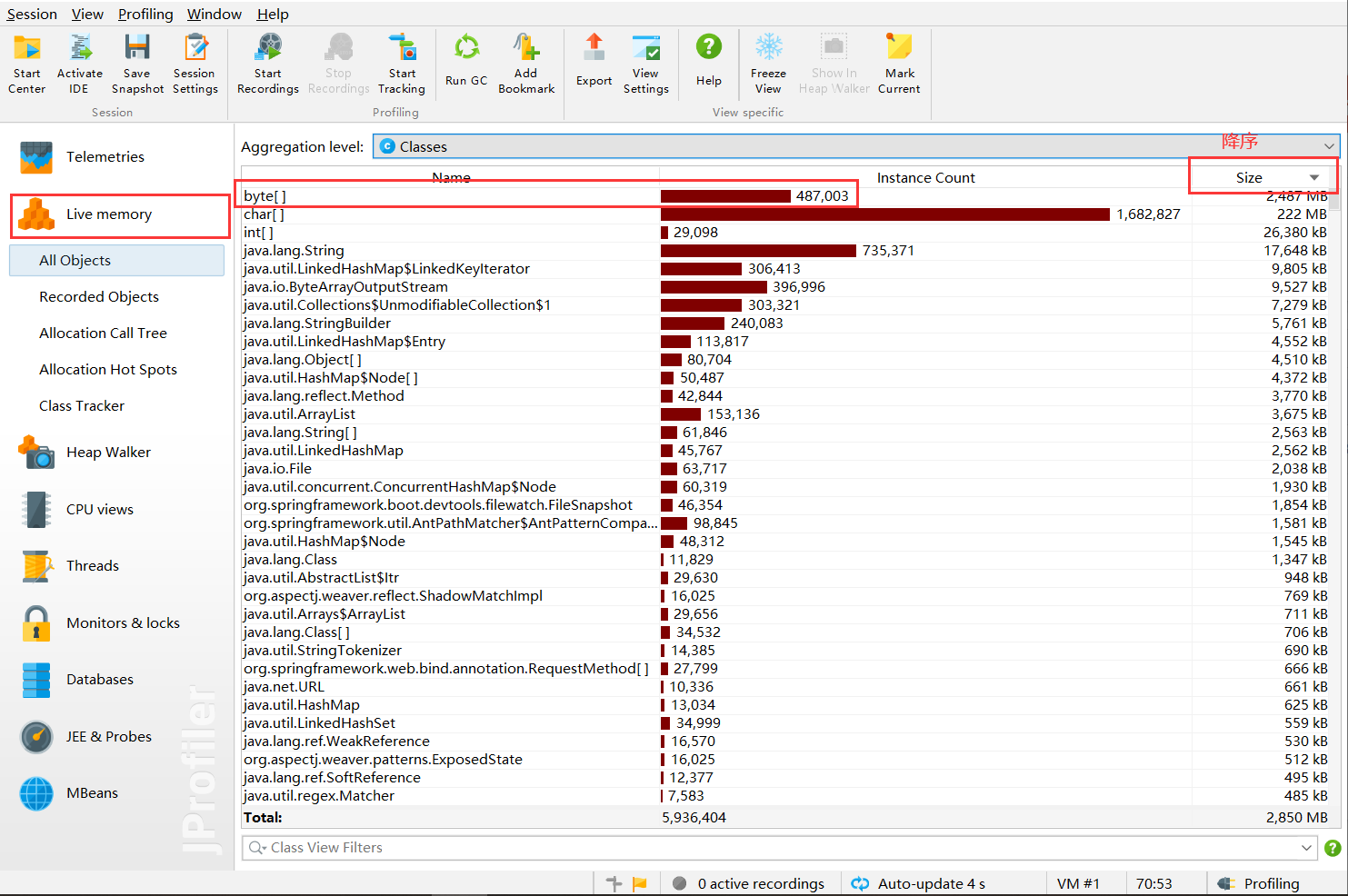
对象分析
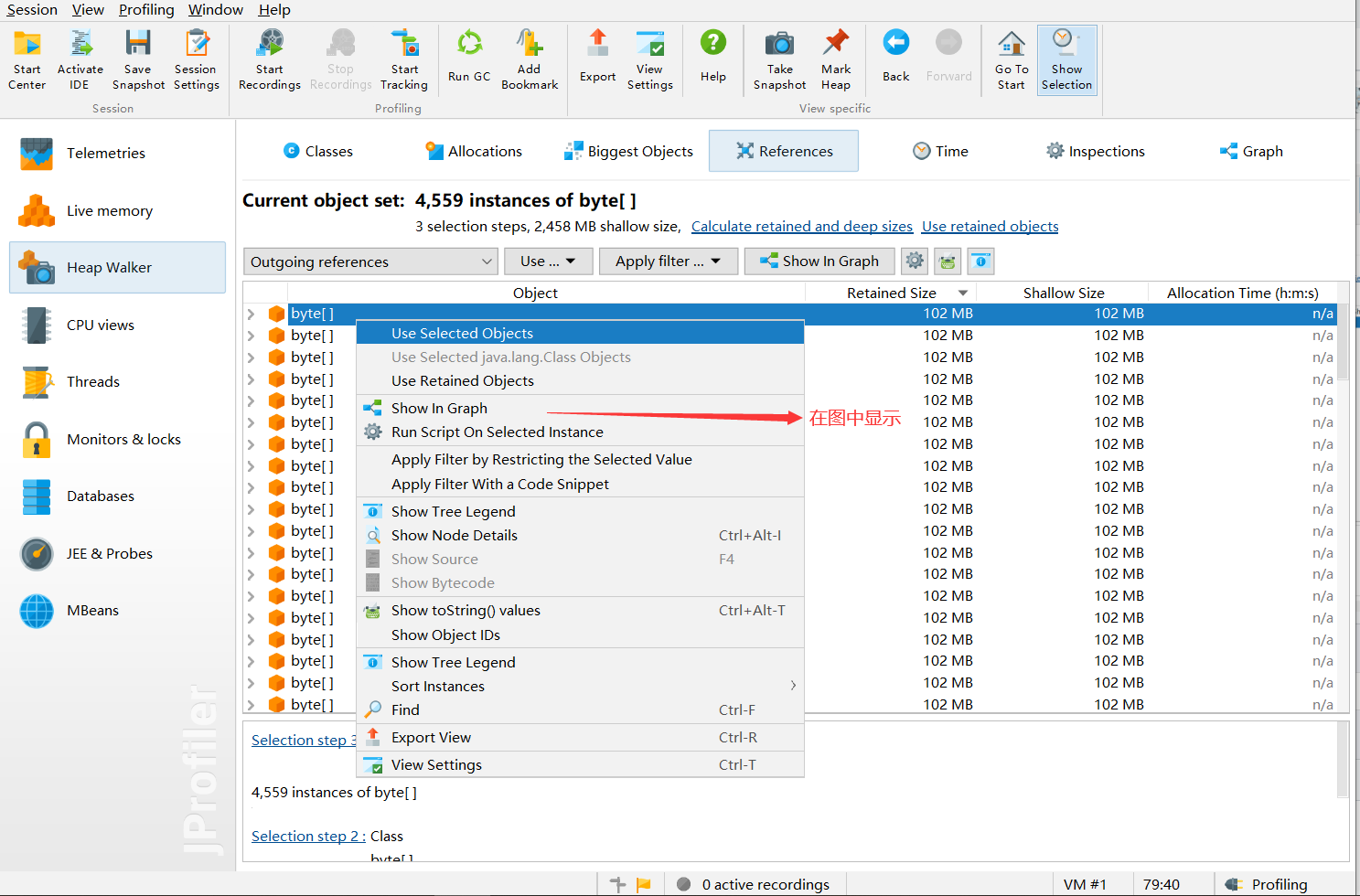
对选中的对象进行选中显示
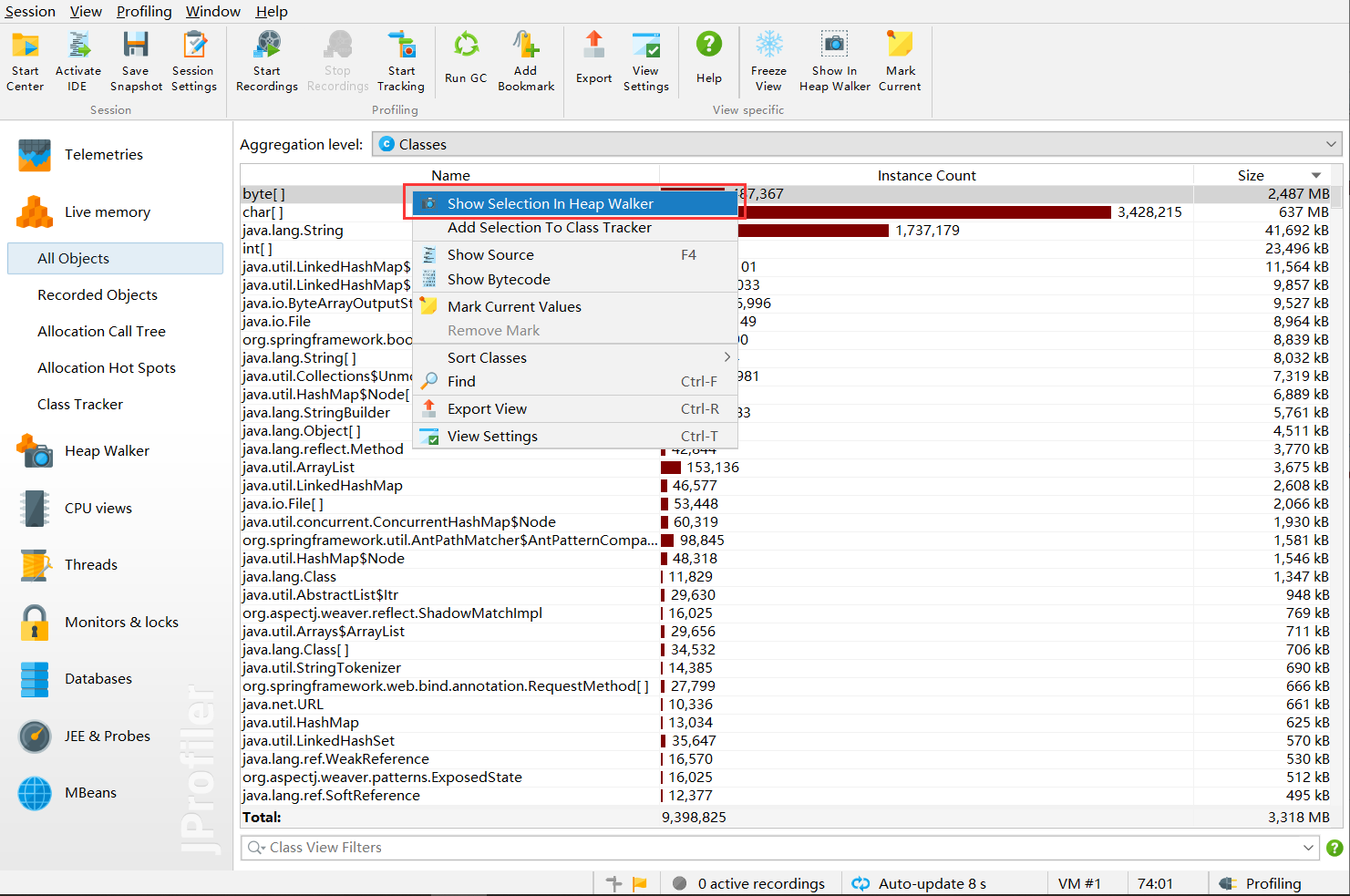 进入界面
进入界面
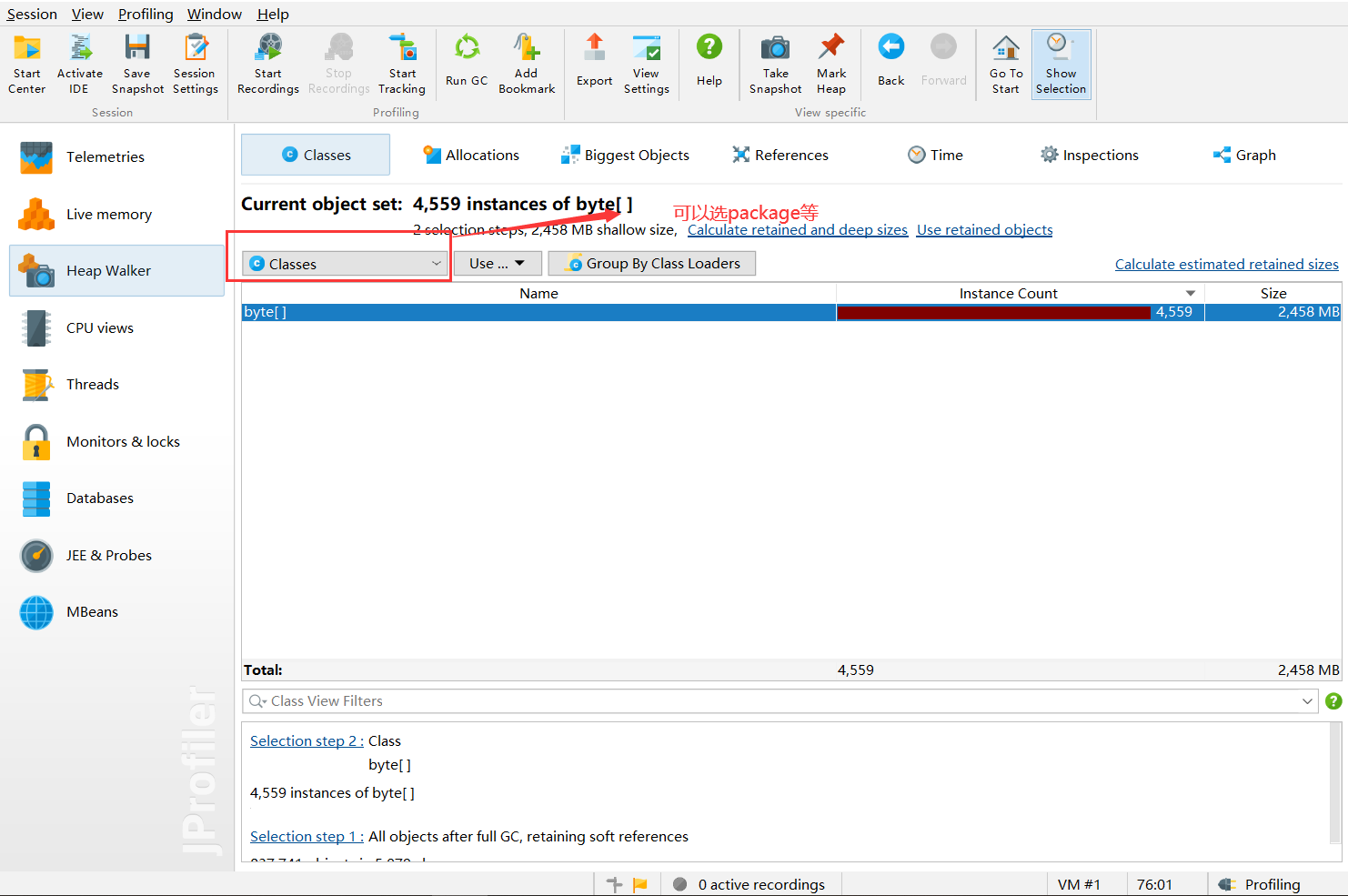
关键点来了
使用选中的对象
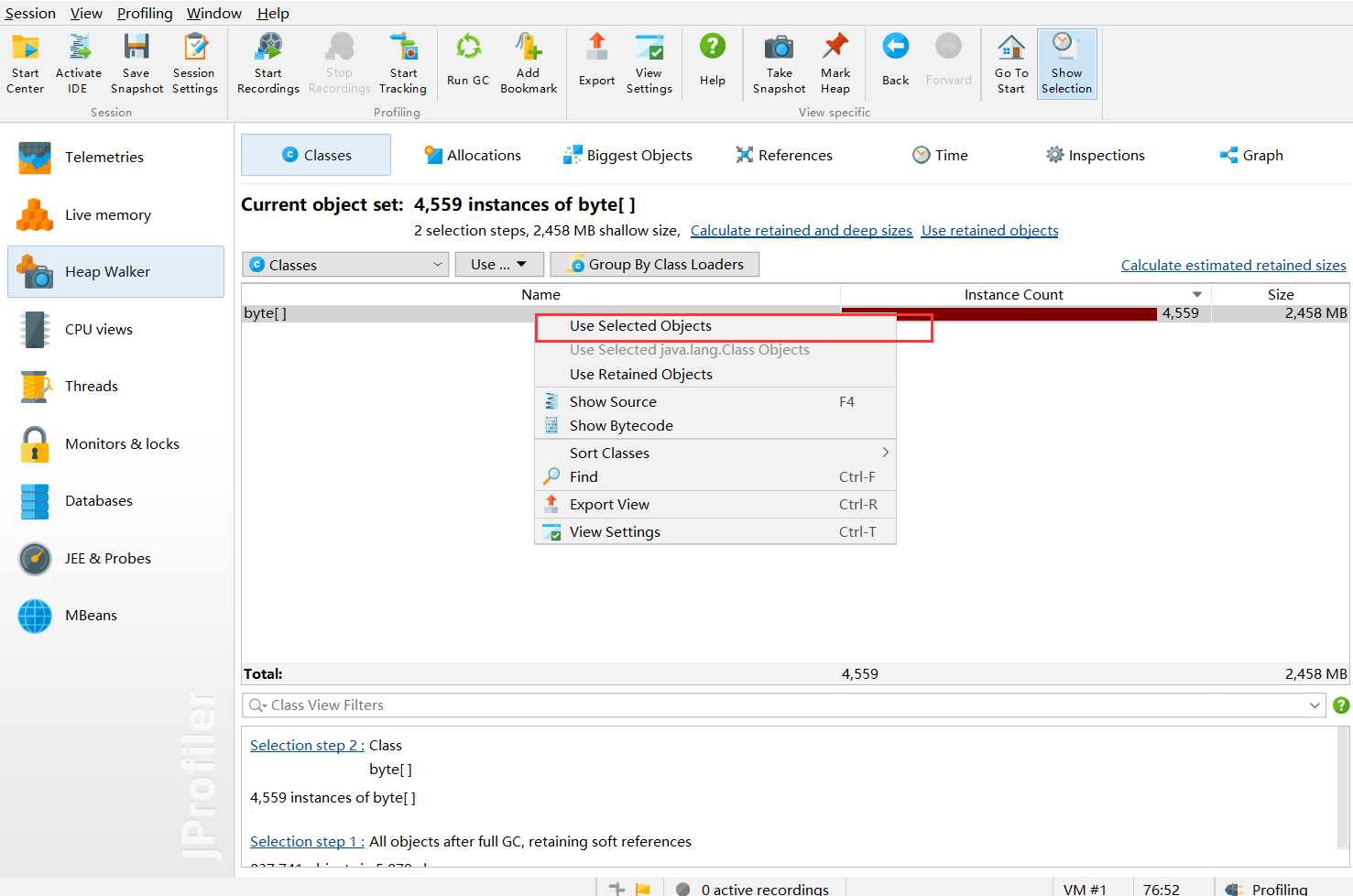 outgoing表示选中对象产生的对象
incoming表示是谁产生的这些对象,这里当然选择的是incoming
outgoing表示选中对象产生的对象
incoming表示是谁产生的这些对象,这里当然选择的是incoming
进入界面
 然后选中其中一个
然后选中其中一个
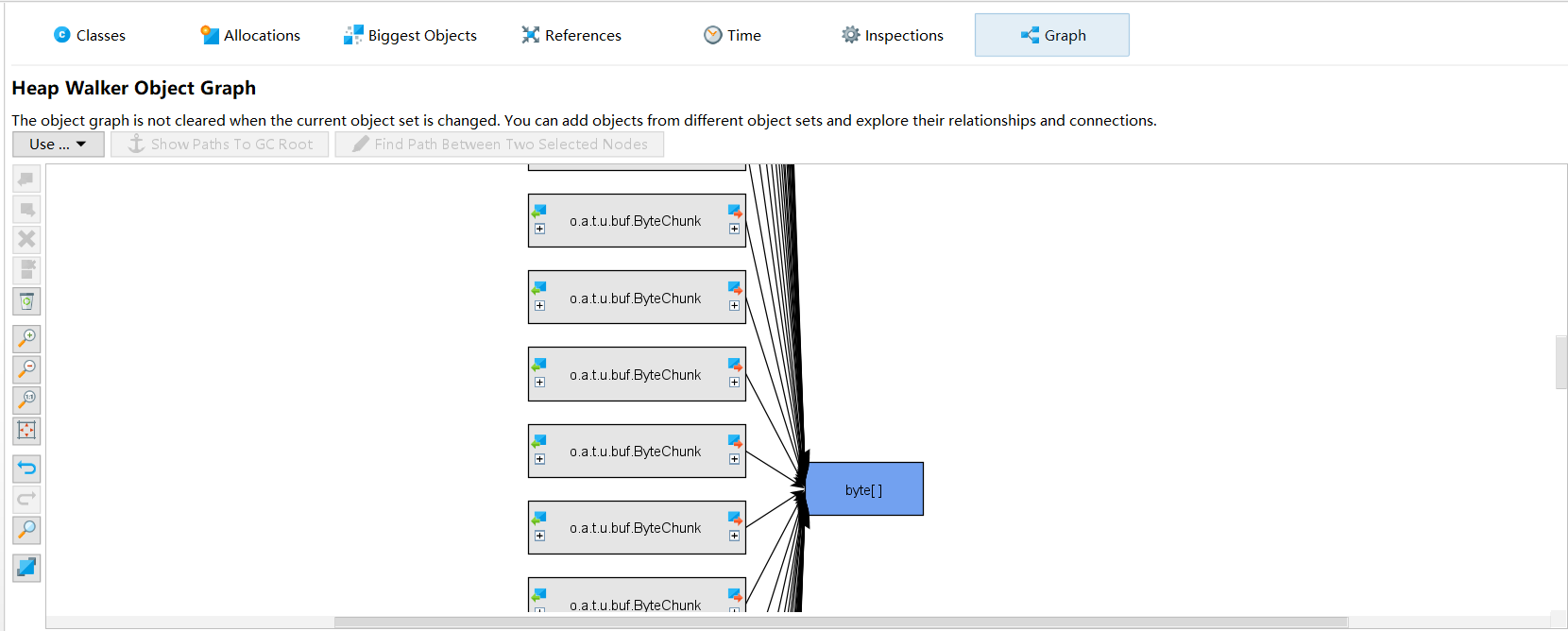
 进入界面
进入界面
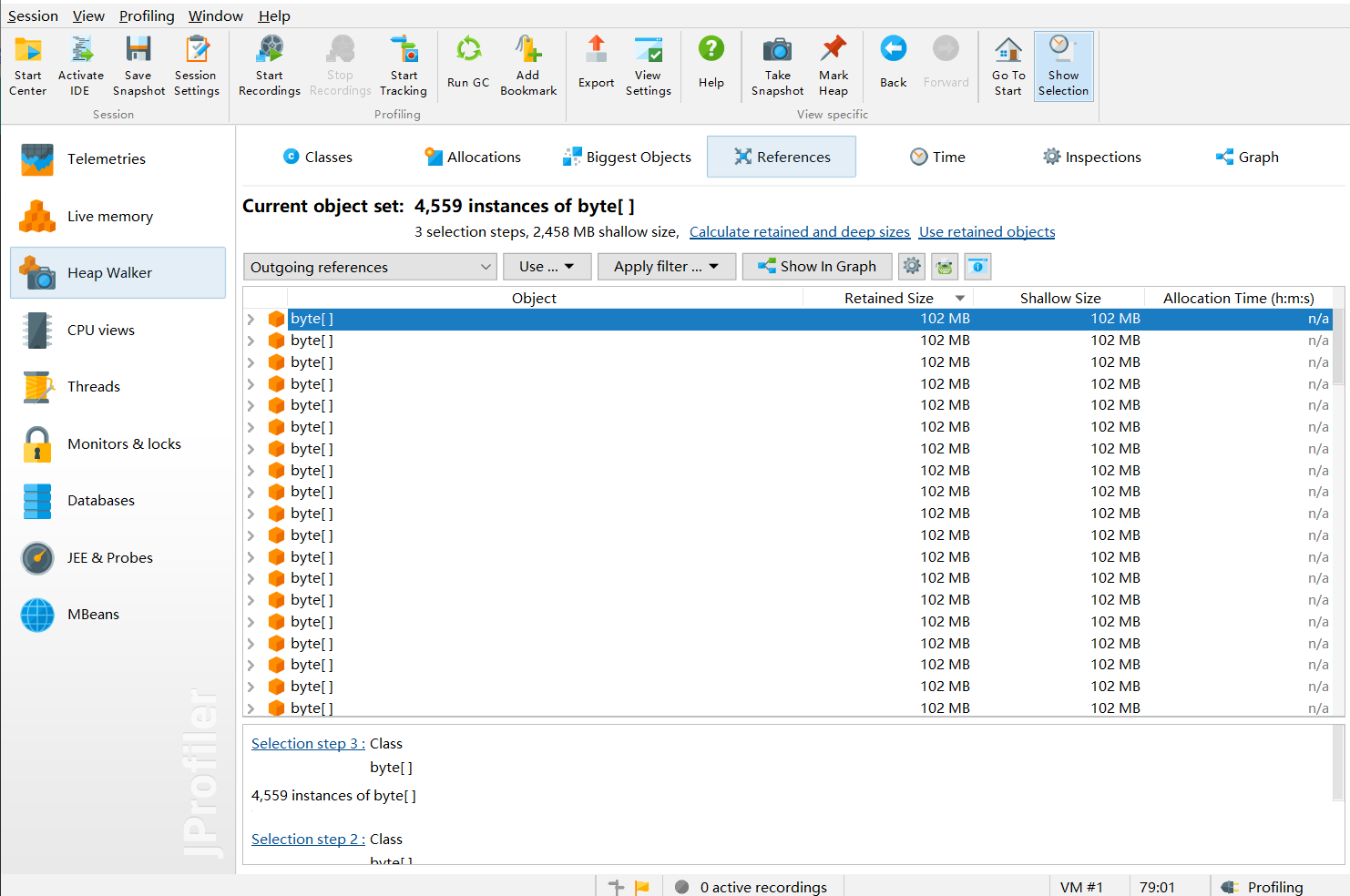
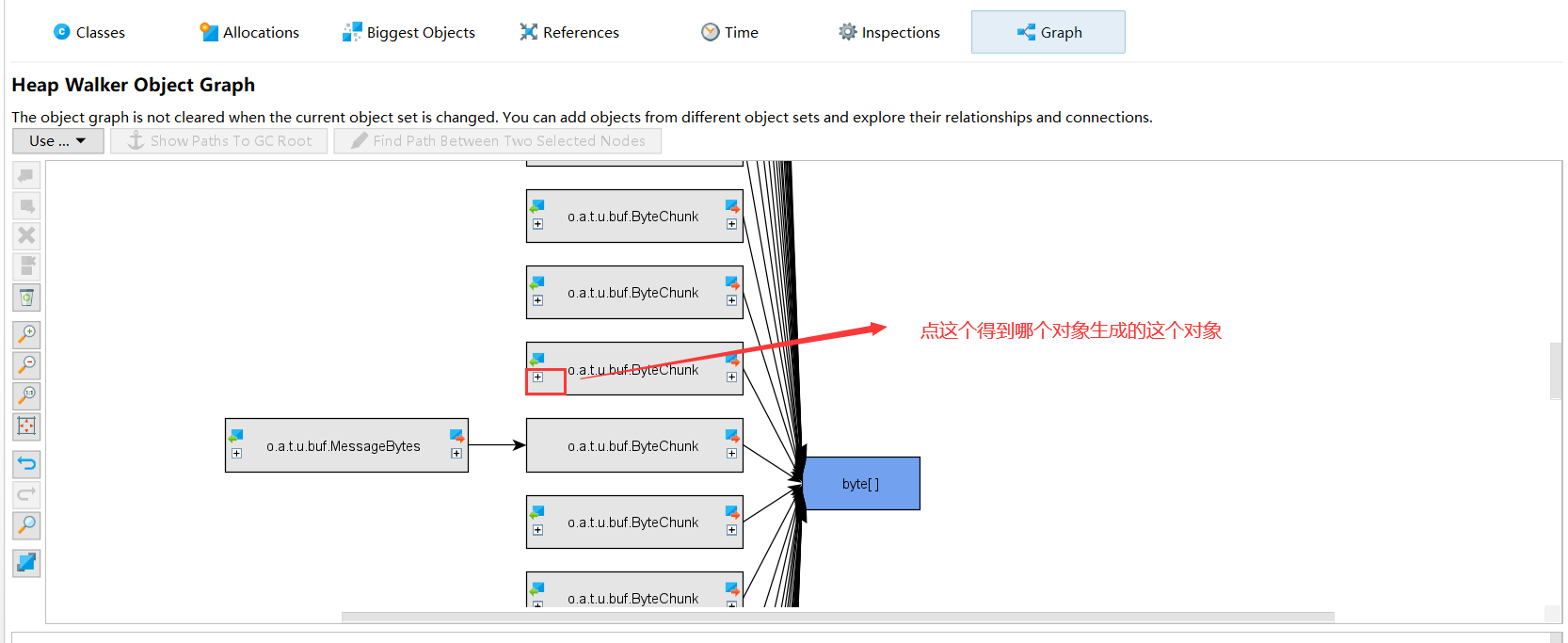 然后我发现一个很重要的东西
然后我发现一个很重要的东西
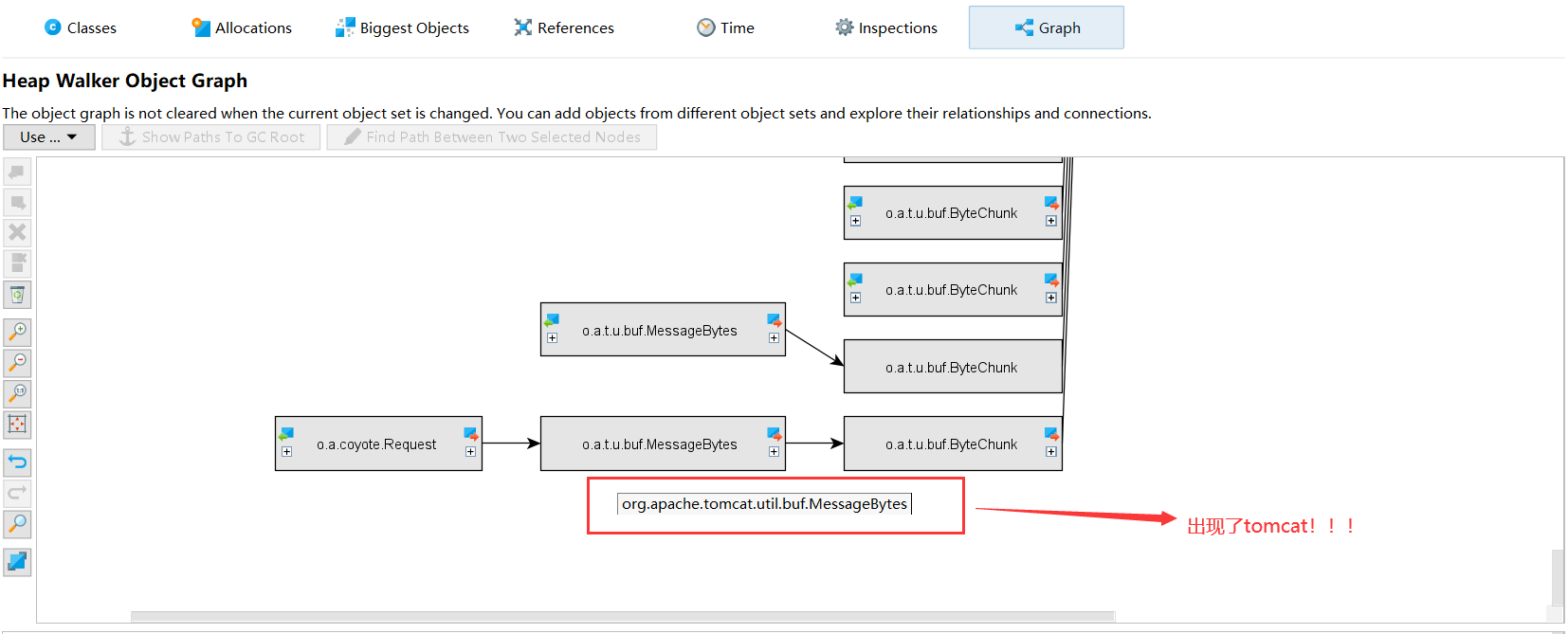
什么,竟然是tomcat产生的!messageBytes,根据我对netty的理解,说的是入站处理器对消息的解码操作。
破案
我再看了其他的byte[]都是如此,难道tomcat才是真凶???可是?! 灵光一闪,想起tomcat的配置项,肯定是什么地方配置有问题
删除所有的tomcat配置项
然后重新进行启动,监控
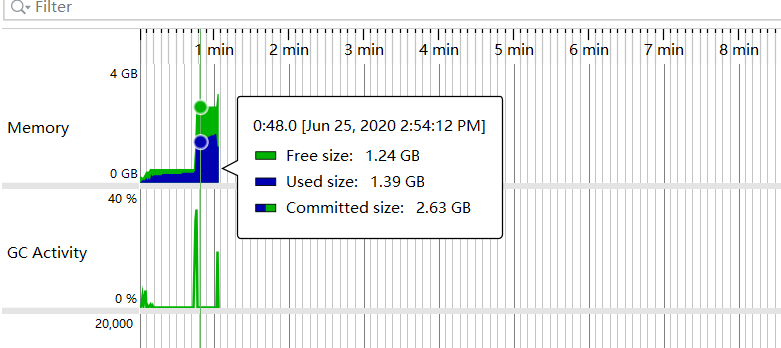 并没有解决,可是byte[]明明指向的就是tomcat,难不成是我搞错了?
我再想想刚刚的messageBytes,意味着请求,当一个请求进来时,导致的内存增加,netty会怎么进行处理呢?
并没有解决,可是byte[]明明指向的就是tomcat,难不成是我搞错了?
我再想想刚刚的messageBytes,意味着请求,当一个请求进来时,导致的内存增加,netty会怎么进行处理呢?
!!!想到了,删除请求的所有配置!!!
比如:
server:
port: 82
max-http-header-size: 102400000
spring:
http:
multipart:
max-file-size: 100MB
max-request-size: 10MB
servlet:
multipart:
max-file-size: 10MB
max-request-size: 20MB
重新启动,请求,监控
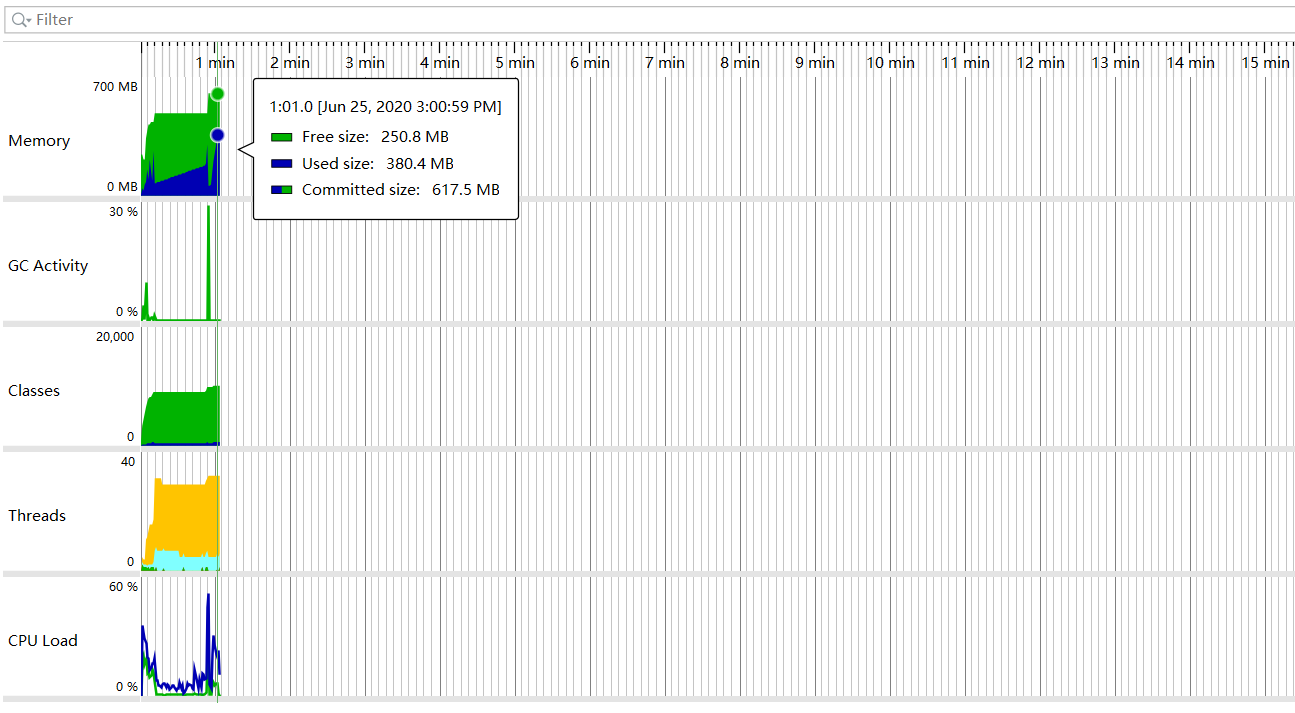
完美!果然,就是某个参数配置出现了问题。现在只需要找出是哪个配置项有问题就行,顶多试5次,运气比较好,第一次就中了,就是
max-http-header-size: 102400000
配置出现的问题,百度一下这个参数的作用
果然我不是被坑的一个人。 看了看git的提交日志,找到同事问了问为啥加这个参数,这些都是后话了,涉及到具体的业务场景,至此结案。
总结
对于参数的一些配置从网上直接copy的时候最好明白参数的含义��,这样才知道为什么要用这个参数,以及针对业务场景进行优化代码。每个小细节的优化才能凑成大的优化,期望调整2,3个参数就能把性能提高2,30%是不现实的,即使是Eleastic-Search也做不到吧。 对于代码底层的理解也能更加方便我们找到问题所在,而不是瞎猜问题,之前出现这个问题后,一直以为是ehcache导致的问题。毕竟程序是死的,真正解决问题的是人。