1. JVM整体结构及内存模型
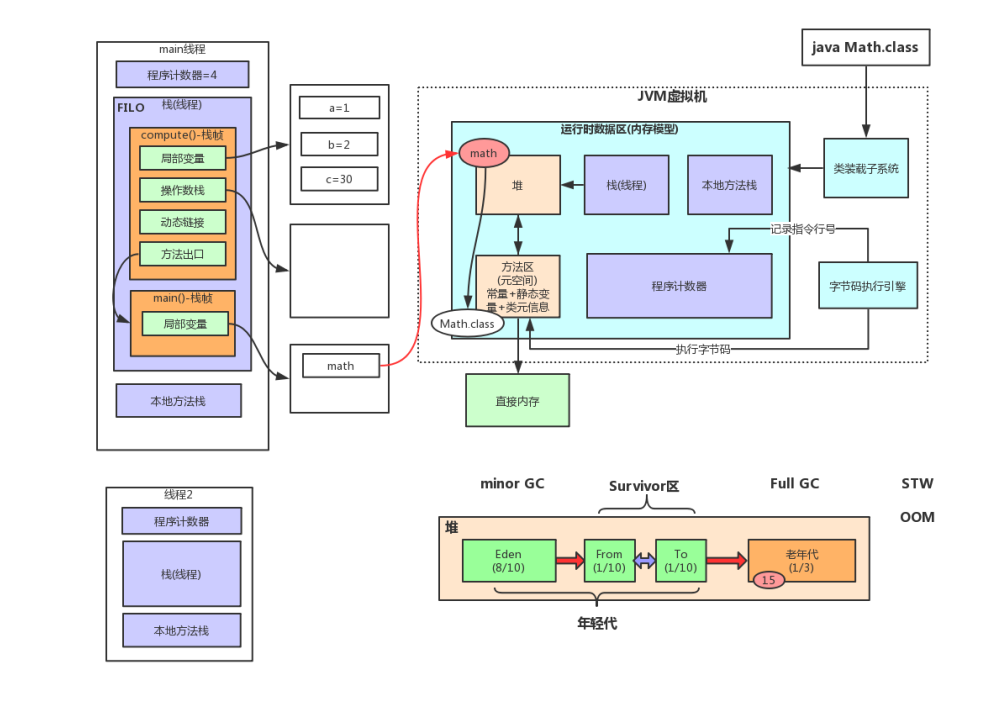
这里从一个类被加载开始说起,当一个类被加载的时候,会被加载到Java的内存区中,也就是运行时数据区。当然 内存区主要分为堆,栈(线程),本地方法栈,方法区(元空间),程序计数器。
1.1 栈(线程)
栈也是一块内存区域,就是当程序开始运行的时候,给运行的这个线程单独开辟的一块内存区域。假如又有新的线程进行产生,也会给新的线程开辟栈空间。 也就说栈是每一个线程进行独享的。
在栈的内部,有栈帧。栈帧存储了方法的局部变量表、操作数栈、动态连接和方法返回地址等信息。这注意看啊,是给方法进行存储的。例如,当一个main()方法启动时,主线程会先给main()方法分配一个栈帧,而栈帧中又调用了compute()方法,那么主线程又会给compute()方法分配一个栈帧。
而且因为根据栈的数据结构,先进后出,意味着,main()方法在栈的底部,compute()方法在main()方法的上方。当compute()方法执行完成之后,便进行出栈。如上图右侧演示。
在栈帧内部,还有小块内存区域,分别是局部变量表,操作数栈,动态链接,方法出口等。
举个例子:
public class Test {
public int compute(){
int a = 1;
int b = 2;
return a+b;
}
public static void main(String[] args) {
Test test = new Test();
int compute = test.compute();
System.out.println(compute);
}
}
在上述代码中,我通过main()方法实例化Test对象,并调用了Test对象的compute()方法。
在这个class文件生成的区域,我们使用 javap -c Test.class,获取class文件反汇编的结果
D:~\demo>javap -c Test.class
Compiled from "Test.java"
public class run.runnable.demo.Test {
public run.runnable.demo.Test();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public int compute();
Code:
0: iconst_1
1: istore_1
2: iconst_2
3: istore_2
4: iload_1
5: iload_2
6: iadd
7: ireturn
public static void main(java.lang.String[]);
Code:
0: new #2 // class run/runnable/demo/Test
3: dup
4: invokespecial #3 // Method "<init>":()V
7: astore_1
8: aload_1
9: invokevirtual #4 // Method compute:()I
12: istore_2
13: getstatic #5 // Field java/lang/System.out:Ljava/io/PrintStream;
16: iload_2
17: invokevirtual #6 // Method java/io/PrintStream.println:(I)V
20: return
}
可以看到,我们编写的代码通过反汇编之后生成了很多指令。这里可以通过JVM指令手册进行查询,
那么compute方法中对应的命令操作是:
iconst_1:int类型常量1压入操作数栈。这句话表达的意思就是,我们虚拟机会给一个常量1放到栈的操作数栈上去istore_1:将int类型值存入局部变量1。也就是说,将操作数栈的常量1,赋值给局部变量1,也就是对应了实际代码的a=1;操作iconst_2:将int类型常量2压入栈。istore_2:将int类型值存入局部变量2。iload_1:从局部变量1中装载int类型值。iload_2:从局部变量2中装载int类型值。iadd:执行int类型的加法。ireturn:从方法中返回int类型的数据。
这里为什么没有局部变量0?
因为局部变量默认放的是this的引用
这里我们在执行指令码的时候,虚拟机中的程序计数器也会跟着变动。
根据以上分析,我们再来看栈中的小的内存区域。
1.1.1 局部变量表(Local Variable Table)
是一组变量值存储空间,用于存放方法参数和方法内部定义的局部变量。并且在Java编译为Class文件时,就已经确定了该方法所需要分配的局部变量表的最大容量。
1.1.2 操作数栈(Operand Stack)
操作数栈是一个后入先出的栈,方法的执行操作都在操作数栈中完成,每一个字节码向操作数栈中写入和写出,就是操作数栈的入栈和出栈。相当于是一个临时的操作区域。
1.1.3 动态连接(Dynamic Linking)
每个栈帧都有一个指向运行时常量池(JVM运行时的数据区域)中该栈所属方法的引用,持有这个引用是为了支持方法调用过程中的动态连接。在Class文件格式的常量池中存有大量的符号引用(1、类的全限定名,2、字段名和属性,3、方法名和属性),字节码中的方法调用指令就是以常量池中指向方法的符号引用为参数。
1.1.4 方法出口(Method Invocation Completion)
只有两种方法可以退出正在执行的方法,一个是执行引擎遇到方法返回字节码指令(return),这个时候会有返回值返回给方法的调用者,这种退出方法称为正常完成出口(Normal Method Invocation Completion)。另一种退出方式是方法遇到了异常并且在此方法异常没有得到处理,无论是JVM虚拟机自己产生的异常或者是使用throw字节码指令产生的异常,只要是在本方法中没有得到处理的异常,在本方法的异常处理器表中没有搜索到匹配的异常处理器,这种导致方法退出的方式称为异常完成出口(Abrupt Method Invocation Completion),这种方式的退出不会给方法的调用者任何返回值。
再举个例子:
就拿上述的代码来说,当我们执行main()方法的时候,我们直到在main()方法中创建了Test对象,那么给main()方法分配的栈帧中的局部变量表中存放的不就是Test对象的引用吗!这样,对于大家都说的那句话 对象都在堆内存上是不是有了更深的理解。当然某些对象也会在栈上。
我们对于JVM参数设置的时候,可以通过参数 -Xss 来设置每个线程栈内存的大小。如果说用满了,就会出现栈内存溢出。
写个例子吧,如下代码进行执行的时候
public class StackOverflowTest {
static int count = 0;
static void redo() {
count++;
redo();
}
public static void main(String[] args) {
try {
redo();
} catch (Throwable t) {
t.printStackTrace();
System.out.println(count);
}
}
}
结果是
java.lang.StackOverflowError
at run.runnable.demo.StackOverflowTest.redo(StackOverflowTest.java:9)
at run.runnable.demo.StackOverflowTest.redo(StackOverflowTest.java:9)
at run.runnable.demo.StackOverflowTest.redo(StackOverflowTest.java:9)
at run.runnable.demo.StackOverflowTest.redo(StackOverflowTest.java:9)
at run.runnable.demo.StackOverflowTest.redo(StackOverflowTest.java:9)
at run.runnable.demo.StackOverflowTest.redo(StackOverflowTest.java:9)
43557
代码中,是一个递归调用。对于主线程的栈中的栈帧会不停的增加,直到溢出。
-Xss设置越小count值越小,说明一个线程栈里能分配的栈帧就越少,但是对JVM整体来说能开启的线程数会更多
1.2 程序计数器(The pc(program counter) Register)
官方解释
The Java Virtual Machine can support many threads of execution at once (JLS §17). Each Java Virtual Machine thread has its own pc (program counter) register. At any point, each Java Virtual Machine thread is executing the code of a single method, namely the current method (§2.6) for that thread. If that method is not native, the pc register contains the address of the Java Virtual Machine instruction currently being executed. If the method currently being executed by the thread is native, the value of the Java Virtual Machine’s pc register is undefined. The Java Virtual Machine’s pc register is wide enough to hold a returnAddress or a native pointer on the specific platform.
解释说明:程序计数器就是一个记录当前线程锁执行的字节码的行号指示器,简单的来说就是记录这个线程跑到哪里了。如果程序是单线程的,则程序计数器并没有实际的意义,代码会一直按照顺序沿着指令执行下去,但是jvm是支持多线程的,当某一个线程执行一半被挂起再次获取到时间片重新执行的时候必须知道它上次执行到哪个地方,因此程序计数器是具备线程隔离的特性,每个线程都有自己的程序计数器。
1.3 方法区
方法区在逻辑上是堆的一部分,但是方法区默认的是不进行垃圾回收或压缩的,所有方法区存放的是一些静态变量、类元信息(每个类的名称,方法信息、字段信息)、常量以及编译后的代码。被所有的线程共享。
1.4 动态链接
在程序运行时期将符号引用替换为直接引用。而与之对应的是静态链接,静态链接则是在class加载到虚拟机的时候,在解析过程,将符号引用替换为直接引用。
如果想直到什么是符号引用替换为直接引用的话,看这里 JVM里的符号引用如何存储?
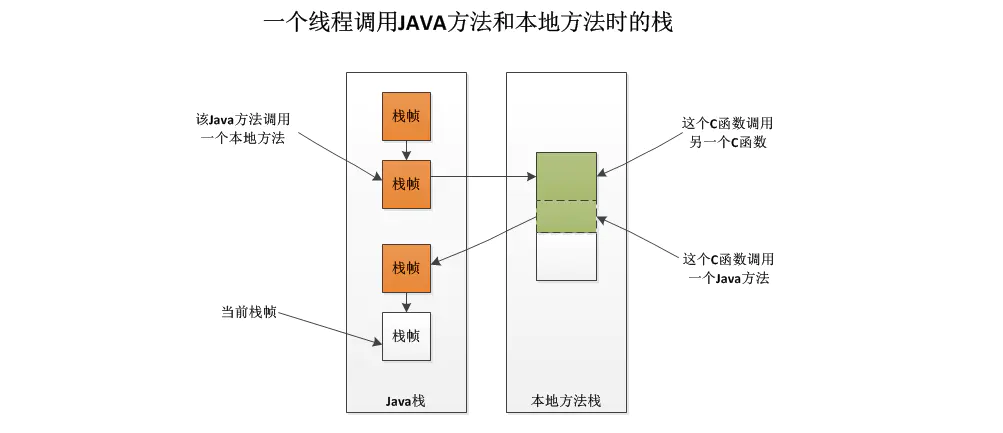
1.5 本地方法栈
是为虚拟机使用到的 Native 方法服务。虚拟机规范中对本地方法栈中的方法使用的语言、使用方式与数据结构并没有强制规定,因此具体的虚拟机可以自由实现它。每一个线程私有。
Navtive 方法是 Java 通过 JNI 直接调用本地 C/C++ 库,可以认为是 Native 方法相当于 C/C++ 暴露给 Java 的一个接口,Java 通过调用这个接口从而调用到 C/C++ 方法。当线程调用 Java 方法时,虚拟机会创建一个栈帧并压入 Java 虚拟机栈。然而当它调用的是 native 方法时,虚拟机会保持 Java 虚拟机栈不变,也不会向 Java 虚拟机栈中压入新的栈帧,虚拟机只是简单地动态连接并直接调用指定的 native 方法。
1.6 堆
当程序新建一个对象时,会将对象放入堆中。
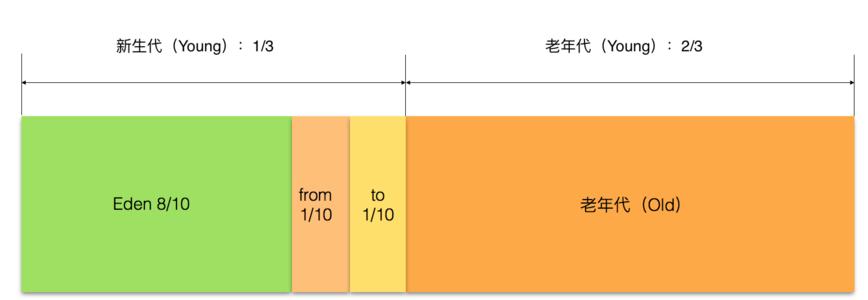
在 Java 中,堆被划分成两个不同的区域:新生代 ( Young )、老年代 ( Old )。
新生代 ( Young ) 又被划分为三个区域:Eden、From Survivor、To Survivor。
JVM的堆被同一个JVM实例中的所有Java线程共享。它通常由某种自动内存管理机制所管理,这种机制通常叫做“垃圾回收”(garbage collection,GC)。JVM规范并不强制要求JVM实现采用哪种GC算法。
2. JVM调优
2.1 JVM内存参数设置
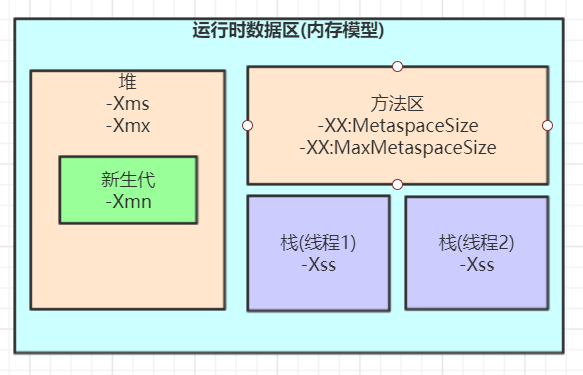
| 参数 | 含义 |
|---|
| -Xss | 每个线程的栈大小 |
| -Xms | 初始堆大小,默认物理内存的1/64 |
| -Xmx | 最大堆大小,默认物理内存的1/4 |
| -Xmn | 新生代大小 |
| -XX:NewSize | 设置新生代初始大小 |
| -XX:NewRatio | 默认2表示新生代占年老代的1/2,占整个堆内存的1/3。 |
| -XX:SurvivorRatio | 默认8表示一个survivor区占用1/8的Eden内存,即1/10的新生代内存。 |
关于元空间的JVM参数有两个:-XX:MetaspaceSize=N和 -XX:MaxMetaspaceSize=N
-XX:MaxMetaspaceSize: 设置元空间最大值, 默认是-1, 即不限制, 或者说只受限于本地内存大小。
-XX:MetaspaceSize: 指定元空间触发Fullgc的初始阈值 (元空间无固定初始大小), 以字节为单位,默认是21M左右,达到该值就会触发full gc进行类型卸载, 同时收集器会对该值进行调整: 如果释放了大量的空间, 就适当降低该值; 如果释放了很少的空间, 那么在不超过-XX:MaxMetaspaceSize(如果设置了的话) 的情况下, 适当提高该值。这个跟早期jdk版本的-XX:PermSize参数意思不一样,-XX:PermSize代表永久代的初始容量。
由于调整元空间的大小需要Full GC,这是非常昂贵的操作,如果应用在启动的时候发生大量Full GC,通常都是由于永久代或元空间发生了大小调整,基于这种情况,一般建议在JVM参数中将MetaspaceSize和MaxMetaspaceSize设置成一样的值,并设置得比初始值要大,对于8G物理内存的机器来说,一般我会将这两个值都设置为256M。
2.2 如何针对一个系统进行JVM调优
首先我们要明白,JVM调优其实就是尽可能的减少Full Gc,让对象在minor GC就被回收掉。
那么对一个系统我们应该怎么去进行分析GC,并进行优化呢?
可以分为几步:
- 高并发产生时间分析
- 在高并发时间段分析会有多少对象产生,也就意味着会有多少对象往伊甸园区进行存放
- 估算设计产生对象大小,比如每笔订单对应一个订单对象,那么就是对订单对象大小的估算
- 对现有机器可容纳的对象和估算会产生的对象进行比较
- 有针对性的进行优化
以一天百万级订单交易量级为例
分析对象产生时间点 。试着估算一下,其实日均百万订单主要时集中在当日的几个小时生成的,假设是3小时,也就是每秒生成100单左右。那么假设我们部署了4台机器,也就是每台每秒大概处理25单左右,往上毛估每秒处理30单。
也就是说每面大概有30个订单对象在堆空间的新生代生成,一个订单对象的大小跟里面的字段多少和类型有关,比如int类型的订单id和用户id等字段,double类型的订单金额等,int类型占用4个字节,double类型占用8字节,初略估计下一个订单对象大概1kb左右,也就是说每秒会有30kb的订单对象分配在新生代中。
估算对象大小和其他关联对象大小产生的实际大小 。真实的订单交易系统肯定还有大量的其他业务对象,比如购物车、优惠卷、积分、用户信息、物流信息等。实际每秒分配在新生代的对象大小应该要再扩大几十倍。假设是30倍,也就是每秒订单系统会往新生代内分配近1M的对象数据,这些数据一般在订单提交完的操作做完之后基本都会成为垃圾对象。
假设部署机器 。我们一般线上服务器的配置用得较多的就是双核4G或4核8G,如果我们用双核4G的机器,因为服务器操作系统包括一些后台服务本身可能就要占用1G多内存,也就是说给JVM进程最多分配2G多点内存,刨开给方法区和虚拟机栈分配的内存,那么堆内存可能也就能分配到1G多点,对应的新生代内存最后可能就几百M,那么意味着没过几百秒新生代就会被垃圾对象撑满而出发minor gc,这么频繁的gc对系统的性能还是有一定影响的。
如果我们选择4核8G的服务器,就可以给JVM进程分配四五个G的内存空间,那么堆内存可以分到三四个G左右,于是可以给新生代至少分配2G,这样算下差不多需要半小时到一小时才能把新生代放满触发minor gc,这就大大降低了minor gc的频率,所以一般我们线上服务器用得较多的还是4核8G的服务器配置。
对于业务拓展情况分析。 假设业务量暴增几十倍,在不增加机器的前提下,整个系统每秒要生成几千个订单,之前每秒往新生代里分配的1M对象数据可能增长到几十M,而且因为系统压力骤增,一个订单的生成不一定能在1秒内完成,可能要几秒甚至几十秒,那么就有很多对象会在新生代里存活几十秒之后才会变为垃圾对象,如果新生代只分配了几百M,意味着一二十秒就会触发一次minor gc,那么很有可能部分对象就会被挪到老年代,这些对象到了老年代后因为对应的业务操作执行完毕,马上又变为了垃圾对象,随着系统不断运行,被挪到老年代的对象会越来越多,最终可能又会导致full gc,full gc对系统的性能影响还是比较大的。
如果我们用的是4核8G的服务器,新生代分配到2G以上的水平,那么至少也要几百秒才会放满新生代触发minor gc,那些在新生代即便存活几十秒的对象在minor gc触发的时候大部分已经变为垃圾对象了,都可以被及时回收,基本不会被挪到老年代,这样可以大大减少老年代的full gc次数
3. 逃逸分析
JVM的运行模式有三种:
- 解释模式(Interpreted Mode):只使用解释器(-Xint 强制JVM使用解释模式),执行一行JVM字节码就编译一行为机器码
- 编译模式(Compiled Mode):只使用编译器(-Xcomp JVM使用编译模式),先将所有JVM字节码一次编译为机器码,然后一次性执行所有机器码
- 混合模式(Mixed Mode):依然使用解释模式执行代码,但是对于一些 "热点" 代码采用编译模式执行,JVM一般采用混合模式执行代码
解释模式启动快,对于需要执行的部分代码,并且大多数代码只会执行一次的情况比较合适。编译模式启动慢,但是后期执行速度快,而且比较占内存,因为机器码的数量至少是JVM字节码的十倍以上,这种模式适合代码可能会被反复执行的场景。混合模式是JVM默认采用的执行代码方式,一开始开始解释模式,但是对于少部分的“热点”代码会采用编译模式去执行,这些热点代码对应的机器码会被缓存起来,下次执行无需再编译,这就我们常见的JIT(Just In Time Compiler)即时编译技术。
对象逃逸分析:就是分析对象动态作用域,当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他地方中。
public User test1() {
User user = new User();
user.setId(1);
user.setName("zhuge");
//TODO 保存到数据库
return user;
}
public void test2() {
User user = new User();
user.setId(1);
user.setName("zhuge");
//TODO 保存到数据库
}
很显然test1方法中的user对象被返回了,这个对象的作用域范围不确定,test2方法中的user对象我们可以确定当方法结束这个对象就可以认为是无效对象了,对于这样的对象我们其实可以将其分配的栈内存里,让其在方法结束时跟随栈内存一起被回收掉。
JVM对于这种情况可以通过开启逃逸分析参数(-XX:+DoEscapeAnalysis)来优化对象内存分配位置,JDK7之后默认开启逃逸分析,如果要关闭使用参数(-XX:-DoEscapeAnalysis)