当你有一张一百万数据的表且没有加索引优化的话,查询一条记录的速度为0.5秒
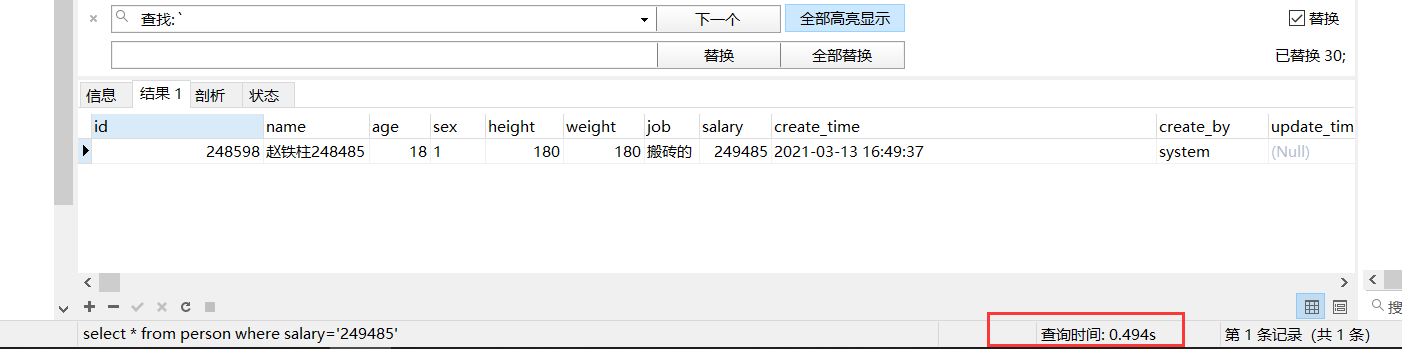
而当你加入索引后,查询一条记录的速度为0.024秒
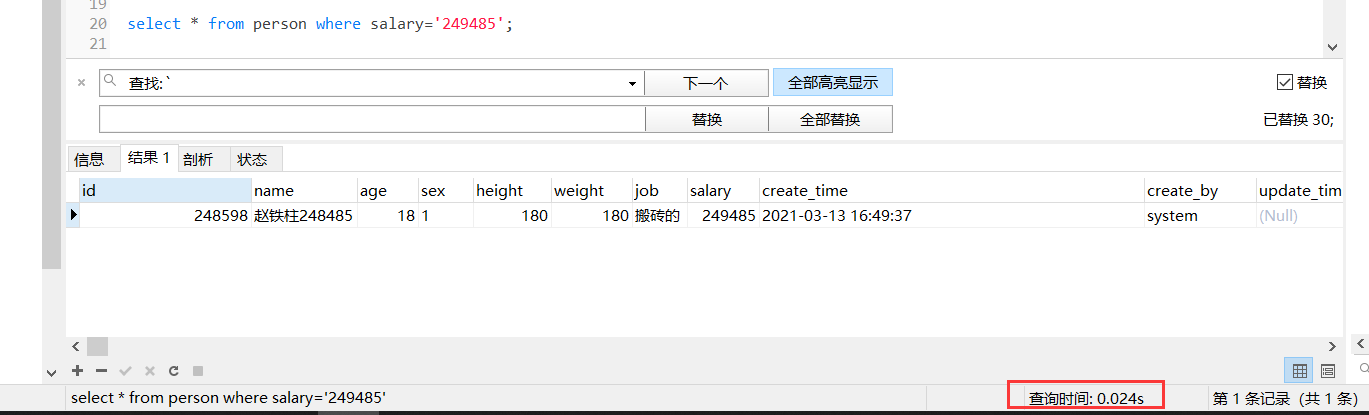
速度相差了20倍,这是一条创建MySql索引的语法
ALTER TABLE <表名> ADD INDEX (<列名>);
在创建索引后,发生了什么?为什么添加索引后能产生这么大的变化?
1. 什么是索引?
要弄懂索引的查询为何如此之快,我们需要先知道索引是什么。
索引在MySql是帮助MySql高效获取数据的排好序的数据结构。而在程序中,包含了很多种的索引,比如二叉树,红黑树,B树,b+树
它为什么能产生如此高效的查询
1.1 那么在mysql中索引的数据结构是怎么样的?
1.1.2 二叉树排序树做索引
当让我们去设计一个存储数据的索引时,可以从最简单的二叉树排序树出发,利用它设计MySql的索引。
二叉排序树(Binary Sort Tree),又称二叉查找树(Binary Search Tree),亦称二叉搜索树。是数据结构中的一类。在一般情况下,查询效率比链表结构要高。
若左子树不空,则左子树上所有结点的值均小于它的根结点的值;
若右子树不空,则右子树上所有结点的值均大于或等于它的根结点的值;
左、右子树也分别为二叉排序树;
当我们往其中持续插入数据时,比如 {1,2,3,4,5,6,7},产生的树形结构如下图
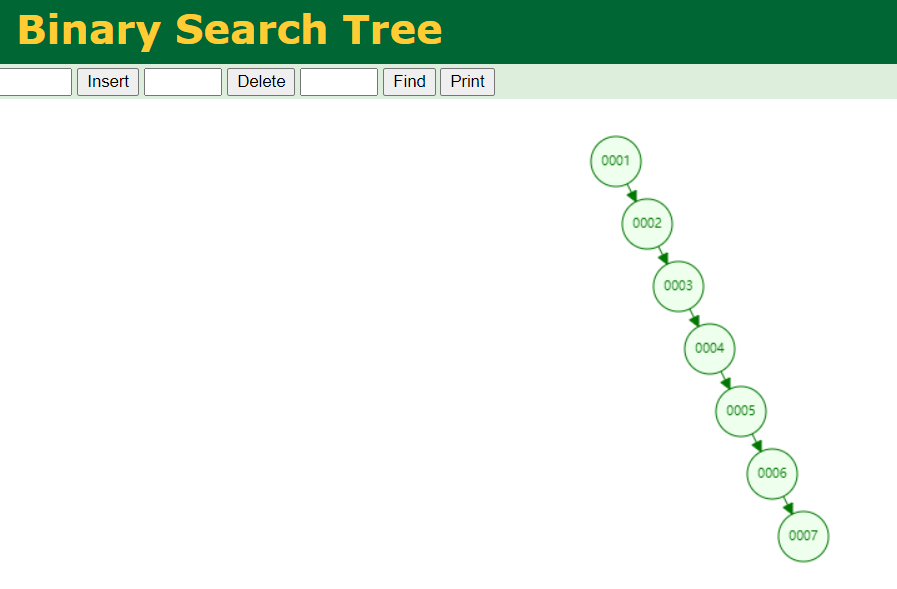
此时我们通过查询当中的某一个数值,比如5,那么将会执行5次才获取到数据,这样的查询效果并不令人满意,因为假如是链表也可以满足这个需求
1.1.3 红黑树做索引
换一种数据结构试试,比如红黑树,也是二叉平衡树,Java用它来实现TreeMap。
红黑树是一种特化的AVL树(平衡二叉树),都是在进行插入和删除操作时通过特定操作保持二叉查找树的平衡,从而获得较高的查找性能。
它虽然是复杂的,但它的最坏情况运行时间也是非常良好的,并且在实践中是高效的: 它可以在O(log n)时间内做查找,插入和删除,这里的n 是树中元素的数目。
红黑树是每个结点都带有颜色属性的二叉查找树,颜色或红色或黑色。 在二叉查找树强制一般要求以外,对于任何有效的红黑树我们增加了如下的额外要求:
性质1. 结点是红色或黑色。
性质2. 根结点是黑色。
性质3. 所有叶子都是黑色。(叶子是NIL结点)
性质4. 每个红色结点的两个子结点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色结点)
性质5. 从任一节结点其每个叶子的所有路径都包含相同数目的黑色结点。
依然用我们之前的数据例子,{1,2,3,4,5,6,7},得到的属性结构如图:
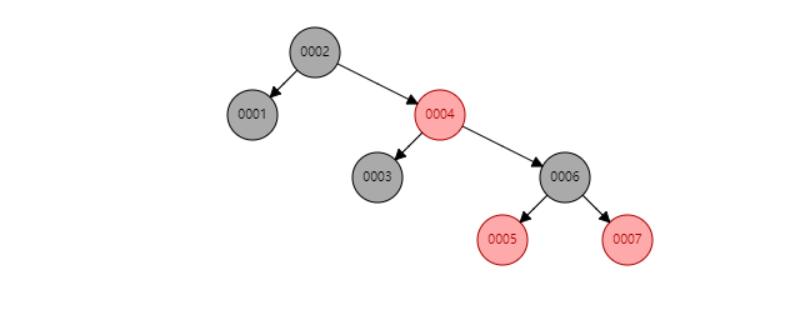
此时我们进行查询数据 5 的话,需要4步才能找到,比二叉排序树要好一些。
那么如果我们使用它作为MySql的索引会发生什么?
如果是100万的数据量,此时,通过公式 $[2^=1000000]$ ,其中n为树形结构产生的高度,当数据量是100万的时候,意味着$[n\approx 19.931569 ]$ ,而树的深度过大而造成磁盘IO读写过于频繁,进而导致效率低下的情况。那么查询一次的轮询也是非常耗时的。
更好的方案去存储索引,能不能将深度 n 控制在3-5 次之间,既要存储大量数据,又要控制深度,那么如果对红黑树进行改造一下呢?
在每个父节点的同级,增加横向节点,意味着产生的效果是这样的
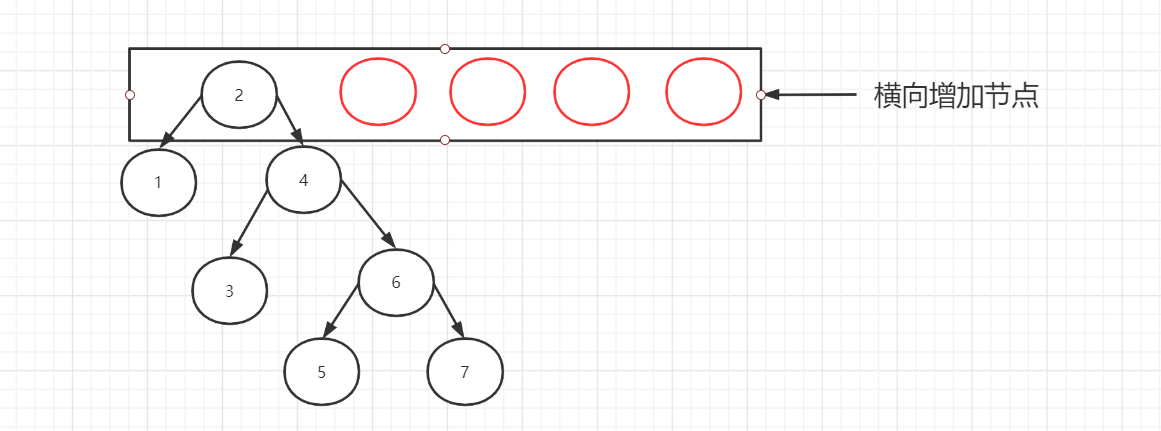
而这就是B-Tree,
1.1.4 B-Tree做索引
B-tree(多路搜索树,并不是二叉的)是一种常见的数据结构。使用B-tree结构可以显著减少定位记录时所经历的中间过程,从而加快存取速度。
B-tree中,每个结点包含:
- 本结点所含关键字的个数;
- 指向父结点的指针;
- 关键字;
- 指向子结点的指针;
对于一棵m阶B-tree,每个结点至多可以拥有m个子结点。各结点的关键字和可以拥有的子结点数都有限制,规定m阶B-tree中,根结点至少有2个子结点,除非根结点为叶子节点,相应的,根结点中关键字的个数为1~m-1;非根结点至少有[m/2]([],向上取整)个子结点,相应的,关键字个数为[m/2]-1~m-1。
通过对B-Tree增加数据后,得到的效果是

这里要说一下B-Tree的特点
- 关键字集合分布在整棵树中;
- 任何一个关键字出现且只出现在一个结点中;
- 搜索有可能在非叶子结点结束;
- 其搜索性能等价于在关键字全集内做一次二分查找;
- 自动层次控制;
由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少利用率,其最低搜索性能为:
其中,M为设定的非叶子结点最多子树个数,N为关键字总数;
所以B-树的性能总是等价于二分查找(与M值无关),也就没有B树平衡的问题
由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并。
这看起来似乎已经满足了我们的要求,B-Tree搜索性能等价于在关键字全集内做一次二分查找,这样的搜索速度是相当快的,但是 B-Tree的每个节点都有data域(指针),这是什么意思呢?
也就是表示B-Tree的每个节点不仅包含了索引元素,而且存储了索引元素对应的数据,如图:
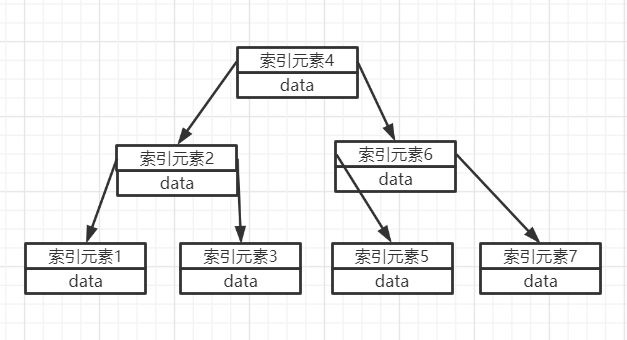
这无疑增加了节点大小,也就是增加了磁盘IO次数,而磁盘IO一次读出的数据量大小是固定的,单个数据变大,每次读出的就少,IO次数增多,一次IO多耗时。
MySql在此基础上进行了改变,使用B+Tree做索引
1.1.5 B+Tree做索引
B+Tree是B树的变种,有着比B树更高的查询性能,来看下m阶B+Tree特征:
- 有m个子树的节点包含有m个元素(B-Tree中是m-1)
- 根节点和分支节点中不保存数据,只用于索引,所有数据都保存在叶子节点中。
- 所有分支节点和根节点都同时存在于子节点中,在子节点元素中是最大或者最小的元素。
- 叶子节点会包含所有的关键字,以及指向数据记录的指针,并且叶子节点本身是根据关键字的大小,从小到大顺序链接。
以上,当中有很重要的两个特征,
根节点和分支节点不保存数据,只用于索引,所有数据都保存在叶子节点中。
叶子节点会包含所有的关键字,以及指向数据记录的指针,并且叶子节点本身是根据关键字的大小,从小到大顺序链接
这便解决了B-Tree中data域的问题
当我们用数据插入的时候,得到的树形结构图是
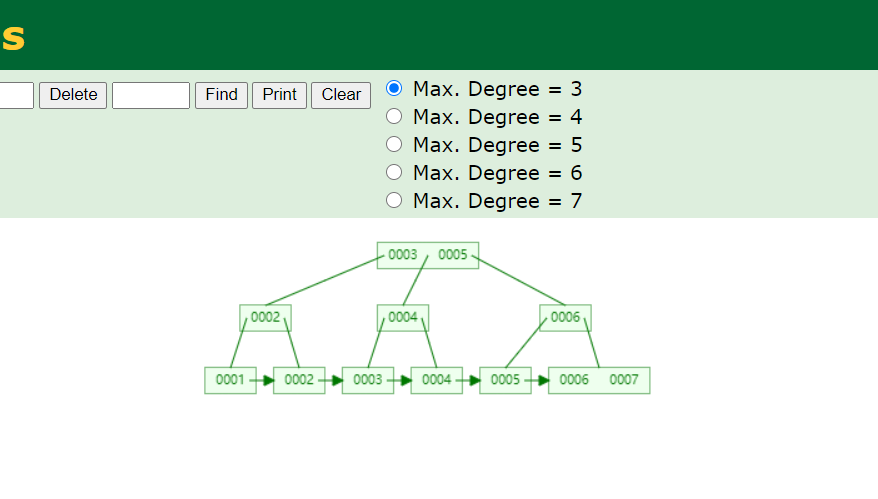
对这张图进行解释说明一下
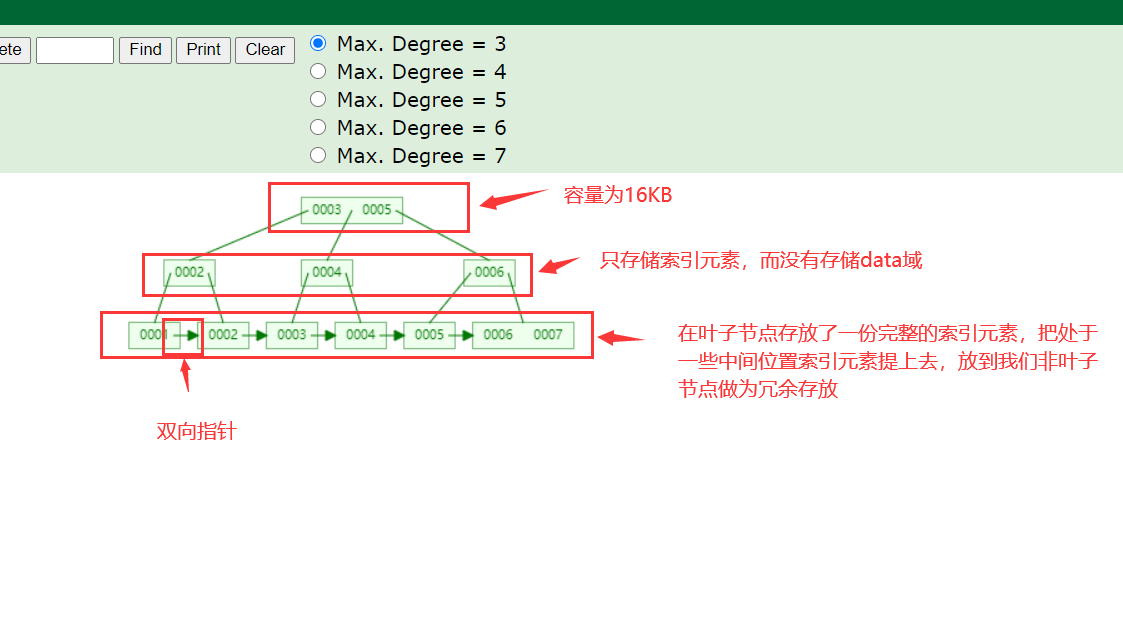
使用语法 show GLOBAL STATUS like 'Innodb_page_size'; 可以知道MySql中默认的页大小容量为多少
1.1.6 为什么B+Tree会这样进行存放?
以索引中的一个节点为例,索引元素占8个字节,而指向下一级索引的指针占4个字节,那么在这一层节点中,可以存储的元素数量有$\frac{16KB}{14B} = \frac{16*1024}{14} \approx 1170 $ ,假设树的高度是 n=3,满载情况下
$$
1170 \cdot 1170 \cdot 16 = 21902400
$$
这样经过3次磁盘IO就能找到2000万中的某一条数据
这样便解决了数据库中查询的问题。
当然,有经验的程序员都知道,在创建MySql索引的时候,我们还可以选择HASH,通过HASH去创建索引。
1.1.7 通过Hash表做索引
哈希算法时间复杂度为O(1),且不只存在于索引中,每个数据库应用中都存在该数据结构。
哈希表也为散列表,又直接寻址改进而来。在哈希的方式下,一个元素k处于h(k)中,即利用哈希函数h,根据关键字k计算出槽的位置。函数h将关键字域映射到哈希表T[0...m-1]的槽位上。
Hash索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以Hash索引的查询效率要远高于B-Tree索引。
那么既然效率这么高,为什么不使用Hash索引而还要使用B+Tree索引呢?
当中的原因有:
- Hash索引仅仅能满足"=","IN"和"<=>"查询,不能使用范围查询。哈希索引只支持等值比较查询,包括**=、 IN 、<=> ** (注意<>和<=>是不同的操作)。 也不支持任何范围查询,例如WHERE price > 100。
由于Hash索引比较的是进行Hash运算之后的Hash值,所以它只能用于等值的过滤,不能用于基于范围的过滤
- Hash索引无法被用来避免数据的排序操作
- Hash索引不能利用部分索引键查询。对于组合索引,Hash索引在计算Hash值的时候是组合索引键合并后再一起计算Hash值,而不是单独计算Hash值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash索引也无法被利用。
- Hash索引在任何时候都不能避免表扫描。Hash索引是将索引键通过Hash运算之后,将 Hash运算结果的Hash值和所对应的行指针信息存放于一个Hash表中,由于不同索引键存在相同Hash值,所以即使取满足某个Hash键值的数据的记录条数,也无法从Hash索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
- Hash索引遇到大量Hash值相等的情况(产生Hash冲突)后性能并不一定就会比BTree索引高。
对于选择性比较低的索引键,如果创建Hash索引,那么将会存在大量记录指针信息存于同一个Hash值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下。
在基于上面的分析后,MySql的存储引擎索引实现并不完全就是这样
在mysql5之后,支持的存储引擎有十几个,但是常用的就那么几种,而且默认支持的也是InnoDB。我们可以通过命令 show ENGINES ; 知道当前MySql支持的存储引擎有哪些
| Engine | Support | Comment | Transacations | XA | Savepoints |
|---|
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| FEDERATED | NO | Federated MySQL storage engine | | | |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
1.2 MyISAM存储引擎
首先这里需要提到的一点是:存储引擎是用来形容表的,而不是数据库的。可以对每一张表设计不一样的存储引擎。
1.2.1 锁的粒度
MyISAM不支持行锁,所以读取时对表加上共享锁,在写入是对表加上排他锁。由于是对整张表加锁,相比InnoDB,在并发写入时效率很低。
1.2.2 数据存储形式
MyISAM采用的是索引与数据分离的形式,将数据保存在三个文件中.frm.MYD,.MYIs。
1.2.3 事务
MyISAM不支持事务。
1.2.4 索引实现
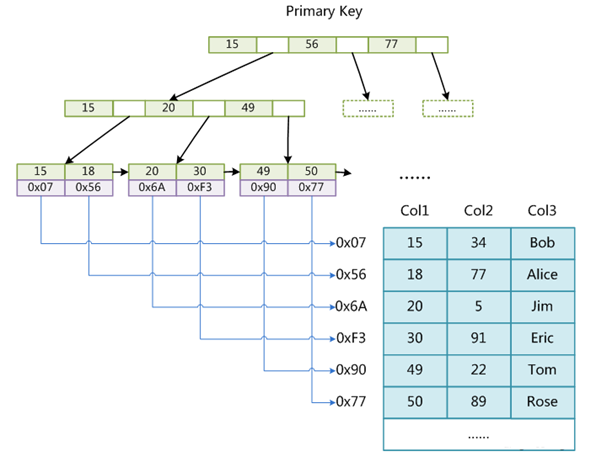
MyISAM是基于非聚簇索引进行存储的。
这意味着,索引中存储的是磁盘文件指针,如下图中叶子节点 15下方的 0x07
1.2.5 其他
MyISAM提供了大量的特性,包括全文索引,压缩,空间函数,延迟更新索引键等。
进行压缩后的表是不能进行修改的,但是压缩表可以极大减少磁盘占用空间,因此也可以减少磁盘IO,从而提供查询性能。
全文索引,是一种基于分词创建的索引,可以支持复杂的查询。
延迟更新索引键,不会将更新的索引数据立即写入到磁盘,而是会写到内存中的缓冲区中,只有在清除缓冲区时候才会将对应的索引写入磁盘,这种方式大大提升了写入性能。
1.3 InnoDB存储引擎
1.3.1 数据存储形式
使用InnoDB时,会将数据表分为.frm 和 idb两个文件进行存储。
1.3.2 锁的粒度
InnoDB采用MVCC(多版本并发控制) 来支持高并发,InnoDB实现了四个隔离级别,默认级别是REPETABLE READ,并通过间隙锁策略防止幻读的出现。它的锁粒度是行锁。
1.3.3 事务
InnoDB是典型的事务型存储引擎,并且通过一些机制和工具,支持真正的热备份。
1.3.4 索引实现
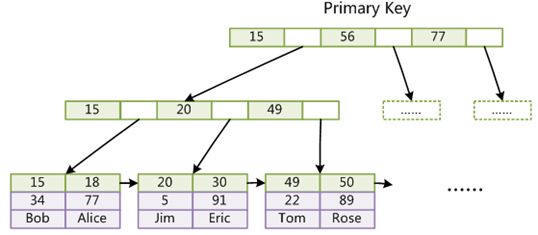
- 表数据文件本身就是按B+Tree组织的一个索引结构文件
- 聚集索引-叶节点包含了完整的数据记录
聚集索引如下图
这里InnoDB涉及到的几个面试题
1.35 为什么InnoDB表必须要有主键?并且推荐整形的自增主键?
首先InnoDB中必须要有主键。B+Tree的索引设计使得表必须需要主键用来平衡B+Tree,如果自己没有设置主键,那么MySql会自行建立一列数据用作主键。
主键递增更适应B+Tree。自增的主键进行插入数据时,会在平衡后进行累加,而UUID因为不是自增,这个B+Tree会不停的进行平衡,消耗资源、时间。
1.3.6 UUID为什么不推荐被当作主键
这是因为UUID比较时会先转化为ASCII码,然后进行比较,这个转化加比较是费时的,而且UUID的字符表更长,更占用空间。
说完了两个MySql的存储引擎之后,还有一种辅助索引,用来告诉InnoDB哪里可以找到与索引相对应的行数据。
1.4 辅助索引(Secondary Index)
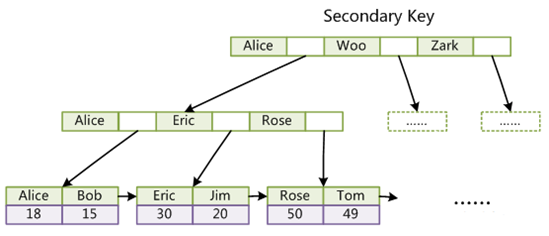
辅助索引说的是,叶子节点中存储主键值,每次查找数据时,根据索引找到叶子节点中的主键值,根据主键值再到聚簇索引中得到完整的一行记录。
辅助索引如下图
1.4.1 为什么要设计辅助索引(二级索引)?
InnoDB在移动行时,无需维护二级索引,因为叶子节点中存储的是主键值,而不是指针。
聚簇索引的叶子节点存储了一行完整的数据,而二级索引只存储了主键值,相比于聚簇索引,占用的空间要少。当我们需要为表建立多个索引时,如果都是聚簇索引,那将占用大量内存空间,所以InnoDB中主键所建立的是聚簇索引,而唯一索引、普通索引、前缀索引等都是二级索引。
也就是说,假如当进行插入数据,修改数据,需要维护主键索引,又要维护非主键索引,那么这对于大数据量的插入绝对是种灾难。所以辅助索引就是为了解决这个问题,插入和修改数据时,只要维护主键索引就行。
1.5 联合索引
联合索引是指对表上的多个列进行索引。
也就是说将多个字段放入叶节点进行索引排序,如下图演示
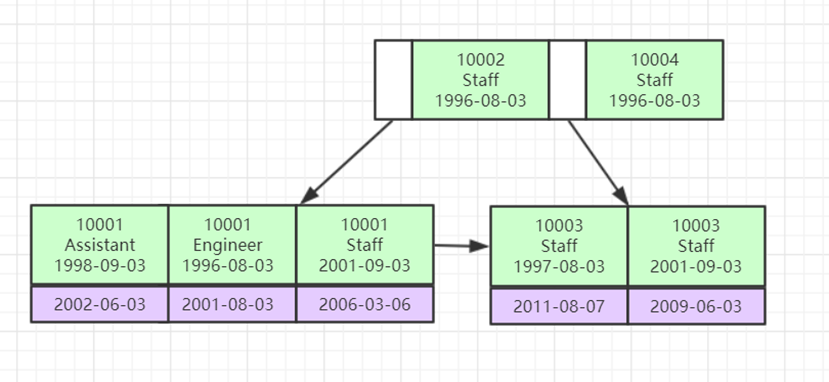
联合索引也是一棵B+树,其键值数量大于等于2。键值都是排序的,通过叶子节点可以逻辑上顺序的读出所有数据。
假设说创建联合索引
ALTER TABLE person ADD INDEX (`a`,`b`);
对于以下查询显然是可以使用(a,b)这个联合索引的
select * from table where a=xxx and b=xxx ;
select * from table where a=xxx;
参考文章:
算法可视化网站
如何计算B+树可以存放多少条数据
什么是B+Tree
mysql索引之哈希索引
浅谈MySQL存储引擎-InnoDB&MyISAM
聚集索引、辅助索引、覆盖索引、联合索引