说在前面
在对Mysql的学习上,我们从书本上得到的理解更多的是下面这样的说法
在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
------------百度百科
都是比喻成图书的目录,但是很少有人说我们索引的本质是什么,以及怎么优化索引。
怎么从零设计一个索引
在上面的百度百科引用中说到了索引是一种数据结构,那么数据结构有很多种,比如栈,堆,表,数组,那么如果是我们自己设计一个索引呢,应该用什么样的数据结构更好呢。
二叉树、红黑树、HASH表,还是B-tree
当然我们已经知道mysql中的存储是用的B+tree,那为什么其他的数据结构是不行的呢?
如果我是mysql的设计者,自然我也肯定使用过其他的数据结构作为存储引擎。
假设我使用的是二叉树作为存储引擎的话,会发生什么呢?
二叉树
这里推荐一个很好用的数据结构可视化网站:数据结构可视化
讲一下二叉树的特性:右边的节点元素是大于父节点的
左边节点元素是小于父节点元素的。
二叉树的查找的时间复杂度是 O(log2N)
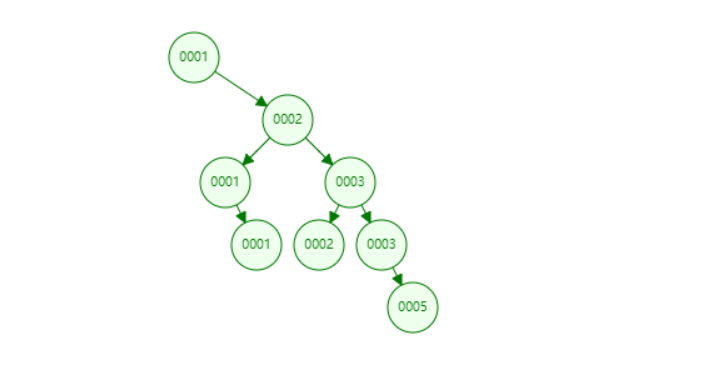
但是在最坏情况下,数字单边增长,二叉树有可能退化为顺序查找,而且就二叉树本身来说,当数据库的数据量特别大时,其层数也将特别大。二叉树的高度一般是 log_2^n,B 树的高度是log_t^((n+1)/2) + 1,其高度约比 B 树大lgt 倍。n 是节点总数,t 是树的最小度数。
红黑树
红黑树其实也是一种二叉树,是平衡二叉树,自动平衡。比如1,2,3,4,5,6,7按照顺序插入,会自动平衡。
在刚刚的那个数据结构可视化工具下,可以看到呈现下面的情况
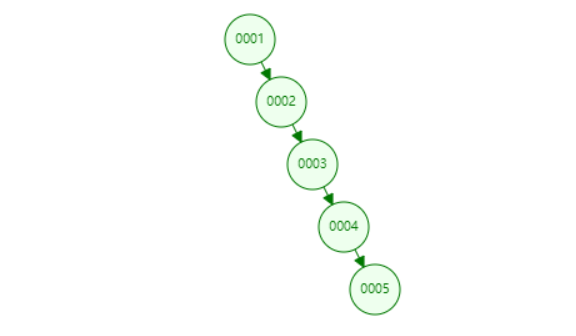
假如使用红黑树作为数据库的索引结构会怎么样呢?
此时会导致一个树的深度问题,假设一百万的数据通过红黑树生成索引,树的高度为2^n=100,0000 计算后得到n便是高度19.93,也就是20层。而且,索引是存在于索引文件中,是存在于磁盘中的。因为索引通常是很大的,因此无法一次将全部索引加载到内存当中,因此每次只能从磁盘中读取一个磁盘页的数据到内存中。而这个磁盘的读取的速度较内存中的读取速度而言是差了好几个级别。
更好的方案,是将查询树的深度控制在3-5次之间,既要存储大量数据,又要控制深度,那么可以对红黑树进行改造。
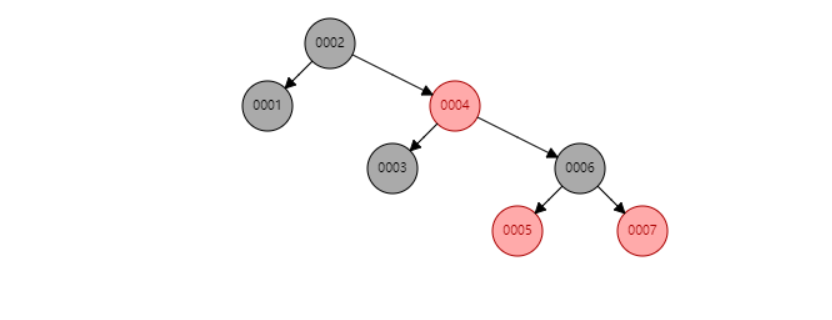
将红黑树的横向增加节点
也就形成了B-tree
B-Tree
下面的内容引用博客:为什么使用 B+ 树或者 B-树做为索引结构?
B-Tree 属于多叉树又名平衡多路查找树(查找路径不只两个)
- 在一个节点中,存放着数据(包括 key 和 data)以及指针,且相互间隔
- 同一个节点,key 增序
- 一个节点最左边的指针不为空,则它指定的节点左右的 key 小于最左边的 key。右边同理。中间的指针指向的节点的 key 位于相邻两个 key 的中间。
- B-Tree 中不同节点存放的 key 和指针可能数量不一致,但是每个节点的域和上限是一致的,所以在实现中 B-Tree 往往对每个节点申请同等大小的空间
- 每个非叶子节点由 n-1 个 key 和 n 个指针组成,其中 d<=n<=2d
如果按照B-Tree进行查找的话
按 key 检索数据,首先与根节点 key 比较,如果找到则返回对应节点的 data,否则对相应区间的指针指向的节点递归进行查找,直到找到节点或找到 null 指针,前者查找成功,后者查找失败
看起来好像已经解决了之前我们说到的深度问题,但是为什么MySql还是没有使用B-tree呢?
B 树在提高 IO 性能的同时,并没与解决元素遍历时效率低下的问题。
【例】若 m=1024,则 lgt=lg512=9。此时若 B-树高度为 4,则平衡的二叉排序树的高度约为 36。显然,若 m 越大,则 B-树高度越小。
②若要作为内存中的查找表,B-树却不一定比平衡的二叉排序树好,尤其当 m 较大时更是如此。
因为查找等操作的 CPU 计算时间在 B-树上是
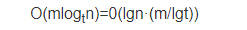
而 m/lgt>1,所以 m 较大时 O(mlogtn)比平衡的二叉排序树上相应操作的时间 O(lgn)大得多。因此,仅在内存中使用的 B-树必须取较小的 m。(通常取最小值 m=3,此时 B-树中每个内部结点可以有 2 或 3 个孩子,这种 3 阶的 B-树称为 2-3 树)
例子来源:B-树的高度及性能分析
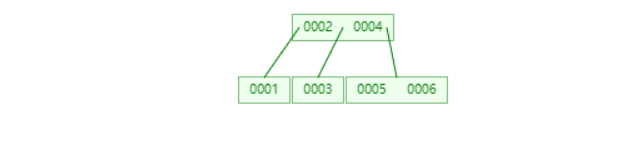
B+Tree
- 非叶子节点不存储数据,只存储索引(冗余),可以放更多的索引
- 叶子节点包含所有的索引
- 叶子节点用指针连接,提高区间访问的性能
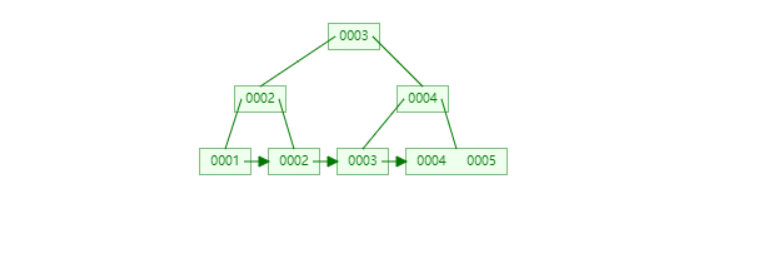
从这张图,有几个比较重要的点需要注意:
- B+Tree在叶子节点存放了一分完整的索引元素
- 把处于一些中间位置索引元素提上去,放到我们非叶子节点作为冗余来存放
- 非叶子节点只存储索引元素,而没有存储索引元素指针,移除元素可以让非叶子节点储存更多的数据
- 叶子节点连接是一个双向指针,意味着正序倒序查找都行
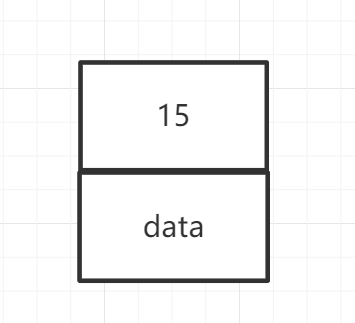
为什么B+Tree会这样进行存放?
以一个索引当中的一部分为例
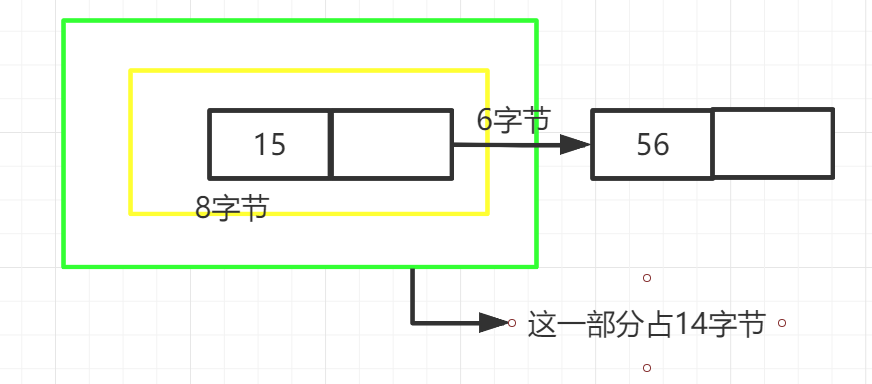
MySql中默认非子结点大小16KB(select GLOBAL STATOS like 'Innodb-page-size'),那么16KB/14B=1170,假设树的高度是3,满载情况下
117011701170=21,902,400